

In the past few weeks, three announcements have changed the conversation around AI and cybersecurity.
- Anthropic announced Project Glasswing, a coordinated effort with AWS, Apple, Broadcom, Cisco, CrowdStrike, Google, JPMorgan Chase, the Linux Foundation, Microsoft, NVIDIA and Palo Alto Networks, backed by one hundred million dollars in usage credits, to apply Claude Mythos Preview to the most critical software in the world. Mythos Preview is Anthropic’s most capable frontier model, which the company has chosen not to release publicly.
- Mozilla used the same model to identify and fix 271 vulnerabilities in a single release of Firefox.
- Cloudflare published a detailed account of running it against more than fifty of its own code repositories.
The message is unambiguous: AI-assisted vulnerability discovery is no longer experimental. It is a defensive practice that serious organizations are adopting now.
At Namirial, we started building our answer to this challenge the same week Claude Opus 4.7 became generally available in mid-April 2026. Four weeks later, we have results worth sharing.
Why this matters for a trust service provider
As a Qualified Trust Service Provider under eIDAS, Namirial operates infrastructure that the European framework explicitly classifies as critical. Every electronic signature we generate, every identity we verify, every timestamp we issue is part of the digital backbone that public administrations, banks, insurers, healthcare systems, and millions of citizens rely on every day.
That position carries an unusual standard of responsibility. The security expectations placed on a QTSP are at least as high as those placed on a global cloud provider, and the regulatory framework, through eIDAS 2.0 and the Critical Entities Resilience directive, expects continuous improvement, not point-in-time compliance.
Like every engineering organization of our scale, our security toolchain includes industry-standard commercial SAST, dependency scanning, secret detection, and a structured security review process for releases. These tools work well for what they are designed to do: catching the long tail of known-pattern defects such as SQL injection, exposed credentials and vulnerable dependencies.
What they consistently do not catch is the harder category: business logic flaws, multi-step exploit chains, subtle cryptographic misuse, design-level issues, and vulnerabilities that span multiple files or modules in ways that pattern-based analysis cannot trace. This is precisely the gap where a reasoning AI model, one that can read code, understand intent, and follow data across boundaries, adds value that traditional tools structurally cannot.
The OWASP Top 10:2025, finalized in January 2026, retains Insecure Design (A06) and adds Mishandling of Exceptional Conditions (A10) as categories that pattern-based analysis structurally cannot detect. These are exactly the classes of finding where reasoning-based AI analysis adds value that traditional tooling does not.
The model we used
Claude Mythos Preview, Anthropic’s most capable frontier model, was announced on 7 April 2026 under Project Glasswing. Access has been restricted to a limited group of platform partners and is not generally available. Nine days later, on 16 April 2026, Anthropic made Opus 4.7 generally available.
Opus 4.7 is the model we used for the pipeline described in this post. It is not Mythos, and unlike Mythos it has not demonstrated the same frontier-level capability at security tasks. It is, however, the most capable generally available model from Anthropic at the time of writing, and we wanted to understand what could be achieved with it on real production codebases.
The pipeline runs on Claude models hosted in European AWS regions via Amazon Bedrock, under commercial terms that ensure our code is not used to train the underlying model and is not retained beyond the inference operation. All source material remains under Namirial’s control throughout the analysis.
Note added at publication: on 28 May 2026, as this article was being finalised, Anthropic released Opus 4.8 as its most capable generally available model. The changes most relevant to this work are not about raw capability. Opus 4.8 is reported to make fewer unsupported claims and to flag its own uncertainty more readily, which bears directly on the adversarial-validation stage and false-positive rate described above, and its new parallel sub-agent orchestration mirrors the multi-agent shape our pipeline already relies on. The results in this post were produced on Opus 4.7; re-baselining the pipeline on 4.8 is our immediate next step.
What we built
We designed an AI-assisted security pipeline that runs nine specialized agents in parallel against our codebases, then validates and consolidates their findings through several independent review stages. Without going into engineering detail, the architecture follows a principle that the security community is converging on: separate fast pattern detection, deep semantic reasoning, and adversarial validation as distinct stages, rather than relying on a single all-purpose AI agent.
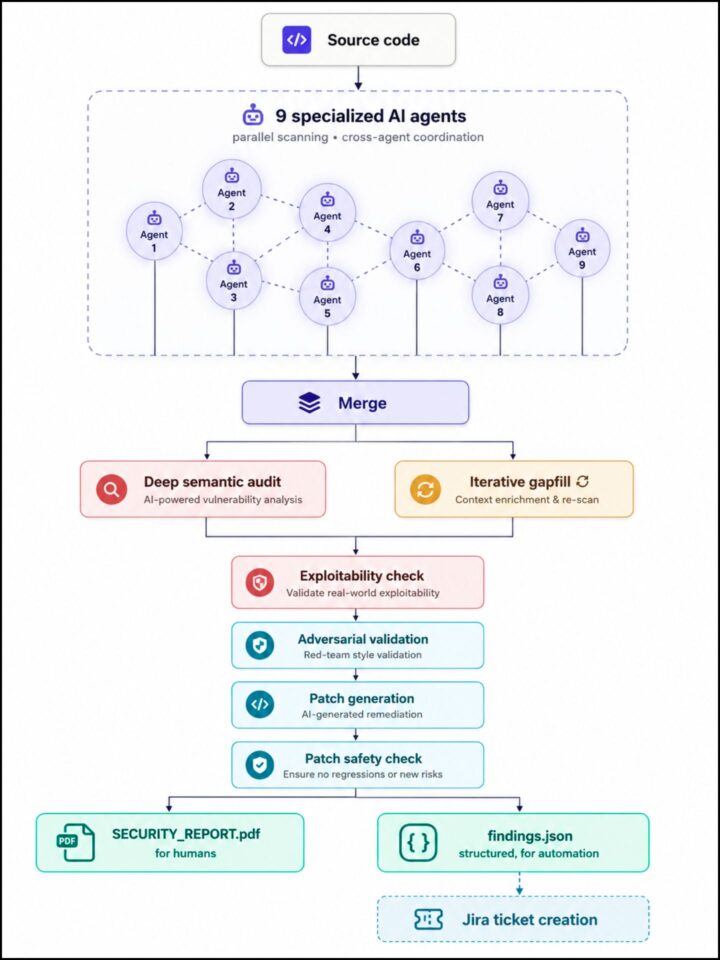
The pipeline produces two outputs: a human-readable PDF report and a structured JSON feed that automatically opens tickets in our issue tracker, routing each finding to the right team without manual triage. This separation matters more than it sounds. The AI surfaces vulnerabilities, but the engineering response remains anchored in our existing development workflow.
The architecture is strikingly similar to approaches documented in recent industry writeups on the topic. The convergence is not coincidence: this is the shape that this work needs to take to be effective. It also suggests that the most important variable here is architecture, how the agents are orchestrated, validated and composed, at least as much as the specific underlying model.
What we found
We ran the pipeline against 23 internal repositories, totalling approximately 1.40 million lines of code. The same perimeter was scanned by our commercial SAST platform. All results below were produced within a four-week window, between mid-April and mid-May 2026
The headline comparison: across the perimeter, our commercial SAST identified 17 high or critical findings, all of which were already triaged and resolved through our standard vulnerability management process. The AI pipeline produced 152 candidate findings, of which 136 were confirmed by the code owners and subsequently remediated, that is 8.0× more than the SAST baseline.
Looking at the data per-repository:
- On 22 of 23 repositories, the AI pipeline identified more high or critical findings than the commercial SAST.
- On 15 of 23 repositories, the commercial SAST reported zero high or critical findings, while the AI pipeline identified between 2 and 13 confirmed findings on each.
- On 1 repository, the commercial SAST identified marginally more findings than the AI pipeline (4 vs 3). It is the only case in our dataset where the traditional tool outperformed the AI pipeline, and the gap is one finding.
- The 17 commercial SAST findings were concentrated on just 8 of the 23 repositories.
What the AI pipeline found that pattern-based scanning could not
Within the 152 candidate findings surfaced by the AI pipeline, 70 (46%) came exclusively from the deep semantic audit stage: vulnerabilities identified by an agent reasoning about code intent and cross-file data flow, not by pattern matching. This is the category where AI analysis adds value that traditional tools structurally cannot.
The remaining 82 findings came from the specialized parallel agents covering injection, deserialization, cryptography, SSRF, XXE, authentication, authorization, supply chain dependencies, infrastructure-as-code and exception handling.
The categorical picture
The most important takeaway is not the 8.9× ratio in isolation, but the categorical distribution. On the fifteen repositories where the commercial SAST reported clean, the AI pipeline surfaced:
- Authentication and authorization defects with non-obvious ownership chains
- Cryptographic operations using the right algorithm in the wrong way
- Trust boundary violations where untrusted data flows into a security decision across files
- Fail-open exception handling on critical paths
- Insecure design patterns: the entire OWASP A06:2025 category by definition
The 17 findings the commercial SAST did identify were precisely the kind of textbook defect where pattern matching with decade-refined rules remains genuinely strong. We are not arguing the commercial tool is broken: it covers a narrow band of risk extremely well, and a much broader band of risk not at all.
The two approaches are complementary, not substitutes. Our roadmap retains our commercial SAST for pattern-rich categories where its rules are mature and uses the AI pipeline for what it uniquely surfaces.
Two numbers we publish without dressing them up:
- The adversarial validation stage rejects approximately 33% of candidate findings. Before any finding reaches a human reviewer, an independent agent attempts to disprove it, acting as a skeptical peer reviewer rather than as a finder. About one third of initially-flagged candidates do not survive this stage and are dropped from the final report. The 152 high/critical findings cited above are the ones that did. We consider this stage a feature, not an embarrassment: without it, the false positive rate visible to engineers would be substantially higher.
- The perimeter compared here is the subset of our codebase where both tools were applied in directly comparable conditions. Our commercial SAST currently covers additional repositories that the AI pipeline has not yet been run against. The comparison is meaningful within its scope, but it is not a platform-wide audit.
What this means in practice
The four weeks we have spent running this pipeline against our repositories have left us with a few practical conclusions.
Multi-agent AI security analysis works, and works well, when the architecture is designed correctly. The pattern that emerges across our results, Cloudflare’s writeup, and Mozilla’s Firefox work is the same: parallel specialized detection, semantic deep audit, adversarial validation, structured reporting. A single all-purpose agent gives noticeably worse results than this layered approach.
The technology complements rather than replaces traditional SAST. The 17 findings our commercial SAST identified are real and valuable, and the rules behind them have been refined over a decade of production use. The 152 findings the AI pipeline surfaced are also real, and they cover categories that pattern-based analysis structurally cannot. Both belong in a serious security program.
The OWASP Top 10:2025 update, with its new emphasis on supply chain failures, exceptional condition handling and insecure design, reinforces this complementarity. The new categories are precisely the ones where reasoning-based AI analysis adds the most value and where traditional scanning is least effective.
What comes next
The pipeline is not finished. Four weeks of operation is the beginning, not the conclusion of this work. Over the coming quarters we plan to:
- extend coverage to additional repositories beyond the current 23;
- add a dedicated agent for OWASP LLM Top 10 risks (the components of our platform that integrate large language models);
- tighten the integration with our CI/CD so that quick scans gate pull requests and full scans run on release branches, and re-baseline the pipeline on Opus 4.8.
We view AI-assisted security as a permanent capability, not a one-time initiative, and we will continue to invest in it to drive vulnerability detection at the speed of modern attacks.
This work was carried out by Giuseppe Gottardi with the support of his cybersecurity team, and by Gabriele Mariotti, Identity Technical Manager, Trust Services & Technologies, for vulnerability validation.





