

In den vergangenen Wochen haben drei Ankündigungen die Diskussion rund um KI und Cybersicherheit verändert.
- Anthropic kündigte das Projekt „Glasswing“ an, eine gemeinsame Initiative mit AWS, Apple, Broadcom, Cisco, CrowdStrike, Google, JPMorgan Chase, der Linux Foundation, Microsoft, NVIDIA und Palo Alto Networks, die mit Nutzungsgutschriften in Höhe von 100 Millionen Dollar ausgestattet ist und darauf abzielt, „Claude Mythos Preview“ auf die kritischste Software der Welt anzuwenden. „Mythos Preview“ ist das leistungsstärkste Modell von Anthropic, das das Unternehmen jedoch nicht öffentlich veröffentlichen will.
- Mozilla nutzte dasselbe Modell, um 271 Schwachstellen in einer einzigen Firefox-Version zu identifizieren und zu beheben.
- Cloudflare veröffentlichte einen detaillierten Bericht über den Einsatz des Modells in mehr als fünfzig seiner eigenen Code-Repositorys.
Die Botschaft ist eindeutig: KI-gestützte Schwachstellenanalyse ist kein experimenteller Ansatz mehr. Sie ist zu einer defensiven Praxis geworden, die ernsthafte Organisationen bereits heute einsetzen.
Bei Namirial begannen wir mit der Entwicklung unserer Antwort auf diese Herausforderung in derselben Woche, in der Claude Opus 4.7 Mitte April 2026 allgemein verfügbar wurde. Vier Wochen später verfügen wir über Ergebnisse, die es wert sind, geteilt zu werden.
Warum das für einen Trust Service Provider wichtig ist
Als Qualified Trust Service Provider gemäß eIDAS betreibt Namirial Infrastrukturen, die der europäische Rechtsrahmen ausdrücklich als kritisch einstuft. Jede elektronische Signatur, die wir erzeugen, jede Identität, die wir verifizieren, jeder Zeitstempel, den wir ausstellen, ist Teil des digitalen Rückgrats, auf das öffentliche Verwaltungen, Banken, Versicherungen, Gesundheitssysteme und Millionen von Bürgerinnen und Bürgern täglich angewiesen sind.
Diese Position bringt ein außergewöhnlich hohes Maß an Verantwortung mit sich. Die Sicherheitsanforderungen an einen QTSP sind mindestens ebenso hoch wie jene an globale Cloud-Provider, und der regulatorische Rahmen – durch eIDAS 2.0 und die Richtlinie über die Resilienz kritischer Einrichtungen – verlangt kontinuierliche Verbesserung und nicht lediglich punktuelle Compliance.
Wie jede Engineering-Organisation unserer Größenordnung umfasst auch unsere Sicherheits-Toolchain branchenübliche kommerzielle SAST-Lösungen, Dependency-Scanning, Secret Detection sowie einen strukturierten Security-Review-Prozess für Releases. Diese Werkzeuge leisten hervorragende Arbeit bei genau den Aufgaben, für die sie entwickelt wurden: das Auffinden der langen Liste bekannter Schwachstellenmuster wie SQL-Injection, offengelegte Zugangsdaten und verwundbare Abhängigkeiten.
Was sie jedoch systematisch nicht erkennen, ist die schwierigere Kategorie: Fehler in der Geschäftslogik, mehrstufige Exploit-Ketten, subtile kryptographische Fehlanwendungen, Designprobleme und Schwachstellen, die sich über mehrere Dateien oder Module erstrecken und durch patternbasierte Analysen nicht nachvollzogen werden können. Genau in dieser Lücke schafft ein KI-Modell mit Reasoning-Fähigkeiten – eines, das Code lesen, Absichten verstehen und Datenflüsse über Grenzen hinweg verfolgen kann – einen Mehrwert, den traditionelle Werkzeuge strukturell nicht leisten können.
Die OWASP Top 10:2025, die im Januar 2026 fertiggestellt wurde, behält „Insecure Design“ (A06) bei und fügt „Mishandling of Exceptional Conditions“ (A10) als Kategorien hinzu, die durch musterbasierte Analysen strukturell nicht erkannt werden können. Genau bei diesen Arten von Befunden bietet die auf Schlussfolgerungen basierende KI-Analyse einen Mehrwert, den herkömmliche Tools nicht bieten.
Das von uns verwendete Modell
Claude Mythos Preview, das leistungsstärkste Pioniermodell von Anthropic, wurde am 7. April 2026 im Rahmen des Projekts Glasswing angekündigt. Der Zugriff ist auf eine begrenzte Gruppe von Plattformpartnern beschränkt und nicht allgemein verfügbar. Neun Tage später, am 16. April 2026, machte Anthropic Opus 4.7 allgemein verfügbar.
Opus 4.7 ist das Modell, das wir für die in diesem Beitrag beschriebene Pipeline verwendet haben. Es ist nicht Mythos und im Gegensatz zu Mythos hat es bei Sicherheitsaufgaben nicht die gleiche Spitzenleistung gezeigt. Es ist jedoch zum Zeitpunkt der Veröffentlichung dieses Textes das leistungsfähigste allgemein verfügbare Modell von Anthropic, und wir wollten verstehen, was sich damit auf realen Produktions-Codebasen erreichen lässt.
Die Pipeline läuft auf Claude-Modellen, die über Amazon Bedrock in europäischen AWS-Regionen gehostet werden, und zwar zu kommerziellen Bedingungen, die gewährleisten, dass unser Code nicht zum Trainieren des zugrunde liegenden Modells verwendet und nach der Inferenzoperation nicht gespeichert wird. Das gesamte Ausgangsmaterial verbleibt während der gesamten Analyse unter der Kontrolle von Namirial.
Anmerkung bei Veröffentlichung: Am 28. Mai 2026, als dieser Artikel fertiggestellt wurde, veröffentlichte Anthropic Opus 4.8 als sein leistungsfähigstes allgemein verfügbares Modell. Die für diese Arbeit relevantesten Änderungen betreffen nicht die reine Leistungsfähigkeit. Opus 4.8 soll weniger unbegründete Behauptungen aufstellen und seine eigene Unsicherheit leichter kennzeichnen, was sich direkt auf die oben beschriebene Adversarial-Validation-Phase und die Falsch-Positiv-Rate auswirkt, und seine neue parallele Sub-Agenten-Orchestrierung spiegelt die Multi-Agenten-Struktur wider, auf die sich unsere Pipeline bereits stützt. Die Ergebnisse in diesem Beitrag wurden mit Opus 4.7 erzielt; die Neuanpassung der Pipeline an 4.8 ist unser nächster Schritt.
Was wir entwickelt haben
Wir entwickelten eine KI-gestützte Sicherheits-Pipeline, die neun spezialisierte Agenten parallel auf unseren Codebasen ausführt und deren Ergebnisse anschließend über mehrere unabhängige Prüfphasen validiert und konsolidiert. Ohne zu sehr ins technische Detail zu gehen, folgt die Architektur einem Prinzip, auf das sich die Sicherheits-Community zunehmend verständigt: schnelle Mustererkennung, tiefgehendes semantisches Reasoning und adversariale Validierung als getrennte Phasen zu behandeln, anstatt sich auf einen einzigen universellen KI-Agenten zu verlassen.
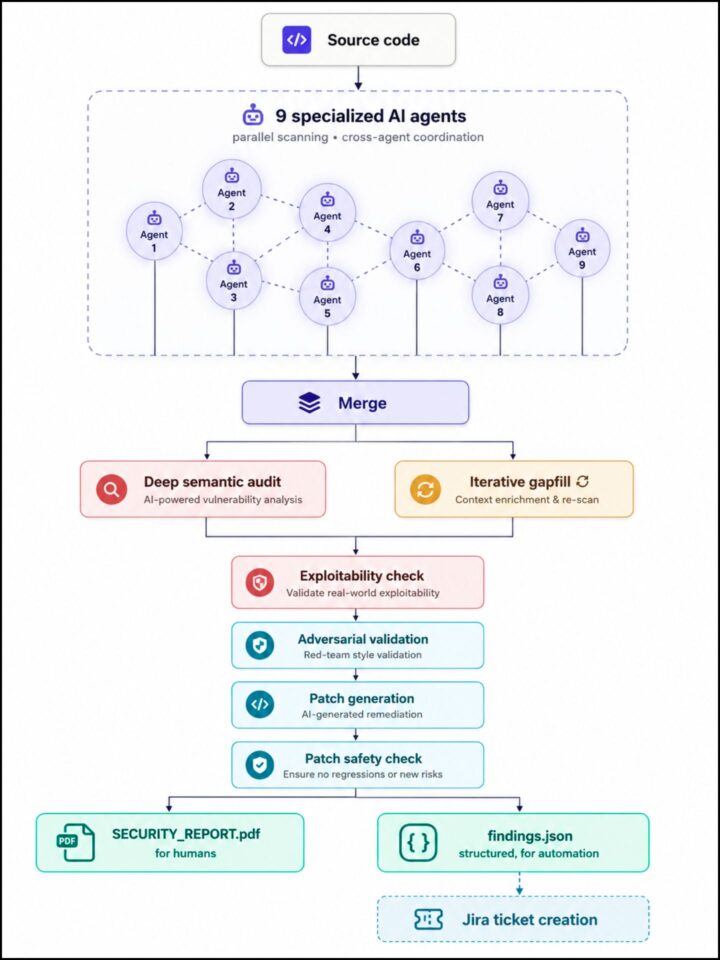
Die Pipeline erzeugt zwei Outputs: einen menschenlesbaren PDF-Bericht und einen strukturierten JSON-Feed, der automatisch Tickets in unserem Issue-Tracker erstellt und jede Feststellung ohne manuelle Triage an das zuständige Team weiterleitet. Diese Trennung ist wichtiger, als sie zunächst erscheint. Die KI identifiziert Schwachstellen, doch die technische Reaktion bleibt in unserem bestehenden Entwicklungsworkflow verankert.
Dass unsere Architektur bemerkenswert ähnlich zu Ansätzen ist, die in aktuellen Branchenanalysen beschrieben werden. Diese Konvergenz ist kein Zufall: Genau diese Form muss diese Arbeit annehmen, um effektiv zu sein. Sie deutet außerdem darauf hin, dass die wichtigste Variable die Architektur selbst ist – also die Art und Weise, wie Agenten orchestriert, validiert und kombiniert werden – mindestens ebenso sehr wie das zugrunde liegende Modell.
Was wir gefunden haben
Wir führten die Pipeline auf 23 internen Repositories mit insgesamt etwa 1,40 Millionen Codezeilen aus. Derselbe Umfang wurde gleichzeitig mit unserer kommerziellen SAST-Plattform analysiert. Alle nachfolgenden Ergebnisse wurden innerhalb eines Zeitraums von vier Wochen zwischen Mitte April und Mitte Mai 2026 erzielt.
Der zentrale Vergleich lautet: im gesamten Perimeter identifizierte unser kommerzielles SAST-Tool 17 hohe oder kritische Befunde, die alle bereits im Rahmen unseres standardmäßigen Schwachstellenmanagementprozesses geprüft und behoben wurden. Die KI-Pipeline erzeugte 152 potenzielle Befunde, von denen 136 von den Code-Eigentümern bestätigt und anschließend behoben wurden – das sind 8,0-mal mehr als bei der SAST-Basislinie.
Betrachtet man die Daten pro Repository:
- In 22 von 23 Repositories identifizierte die KI-Pipeline mehr High- oder Critical-Findings als das kommerzielle SAST.
- In 15 von 23 Repositories meldete das kommerzielle SAST keinerlei High- oder Critical-Findings, während die KI-Pipeline zwischen 2 und 13 bestätigte Findings pro Repository identifizierte.
- In einem Repository identifizierte die kommerzielle SAST geringfügig mehr Befunde als die KI-Pipeline (4 gegenüber 3). Es ist der einzige Fall in unserem Datensatz, in dem das traditionelle Werkzeug besser abschnitt als die KI-Pipeline, und der Unterschied beträgt lediglich ein Finding.
- Die 17 Findings des kommerziellen SAST konzentrierten sich auf nur 8 der 23 Repositories.
Was die KI-Pipeline fand, was patternbasierte Analysen nicht erkennen konnten
Von den 152 durch die KI-Pipeline identifizierten potenziellen Befunden stammten 70 (46 %) ausschließlich aus der Phase des tiefgehenden semantischen Audits: Schwachstellen, die von einem Agenten identifiziert wurden, der über die Absicht des Codes und den datenflussübergreifenden Zusammenhang zwischen Dateien nachdachte – nicht durch Pattern Matching. Genau in dieser Kategorie schafft KI-Analyse einen Mehrwert, den traditionelle Werkzeuge strukturell nicht leisten können.
Die übrigen 82 Findings stammten von spezialisierten Parallel-Agenten für Injection, Deserialisierung, Kryptographie, SSRF, XXE, Authentifizierung, Autorisierung, Supply-Chain-Abhängigkeiten, Infrastructure-as-Code und Exception Handling.
Das kategoriale Bild
Die wichtigste Erkenntnis ist nicht allein das Verhältnis von 8,9×, sondern die Verteilung der Kategorien. In den fünfzehn Repositories, die vom kommerziellen SAST als „clean“ eingestuft wurden, identifizierte die KI-Pipeline:
- Authentifizierungs- und Autorisierungsfehler mit nicht offensichtlichen Ownership-Ketten
- Kryptographische Operationen, bei denen der richtige Algorithmus falsch eingesetzt wurde
- Verletzungen von Trust Boundaries, bei denen nicht vertrauenswürdige Daten über mehrere Dateien hinweg Sicherheitsentscheidungen beeinflussen
- Fail-open-Exception-Handling auf kritischen Pfaden
- Unsichere Designmuster: die gesamte OWASP-A06:2025-Kategorie per Definition
Die 17 Findings, die das kommerzielle SAST identifizierte, waren genau jene klassischen Schwachstellen, bei denen patternbasierte Erkennung mit über ein Jahrzehnt hinweg verfeinerten Regeln tatsächlich stark bleibt. Wir behaupten nicht, dass das kommerzielle Werkzeug „defekt“ sei: Es deckt einen engen Risikobereich extrem gut ab – und einen deutlich größeren Bereich überhaupt nicht.
Die beiden Ansätze ergänzen sich, statt sich gegenseitig zu ersetzen. Unsere Roadmap behält das kommerzielle SAST für Kategorien mit ausgereiften Pattern-Regeln bei und nutzt die KI-Pipeline für jene Risiken, die nur sie sichtbar machen kann.
Zwei Zahlen veröffentlichen wir ganz bewusst ohne Beschönigung:
- Die adversariale Validierungsphase verwirft etwa 33 % der potenziellen Findings. Bevor ein Finding einen menschlichen Reviewer erreicht, versucht ein unabhängiger Agent, es zu widerlegen, und agiert dabei eher als skeptischer Peer Reviewer denn als Finder. Rund ein Drittel der ursprünglich markierten Kandidaten übersteht diese Phase nicht und wird aus dem finalen Bericht entfernt. Die oben genannten 152 High-/Critical-Findings sind jene, die diese Phase bestanden haben. Wir betrachten diese Phase als Stärke und nicht als Schwäche: Ohne sie wäre die für Engineers sichtbare False-Positive-Rate deutlich höher.
- Der hier verglichene Umfang ist der Teil unserer Codebasis, auf den beide Werkzeuge unter direkt vergleichbaren Bedingungen angewandt wurden. Unser kommerzielles SAST deckt derzeit zusätzliche Repositories ab, auf die die KI-Pipeline noch nicht angewandt wurde. Der Vergleich ist innerhalb seines Umfangs aussagekräftig, stellt jedoch kein plattformweites Audit dar.
Was das praktisch bedeutet
Die vier Wochen, in denen wir diese Pipeline auf unsere Repositories angewandt haben, führten zu einigen praktischen Schlussfolgerungen.
Multi-Agenten-KI-Sicherheitsanalyse funktioniert – und funktioniert gut –, wenn die Architektur korrekt entworfen ist. Das Muster, das sich aus unseren Ergebnissen, dem Cloudflare-Bericht und Mozillas Firefox-Arbeit ergibt, ist identisch: parallele spezialisierte Erkennung, tiefgehendes semantisches Audit, adversariale Validierung und strukturiertes Reporting. Ein einzelner universeller Agent liefert deutlich schlechtere Ergebnisse als dieser geschichtete Ansatz.
Die Technologie ergänzt traditionelle SAST-Lösungen, statt sie zu ersetzen. Die 17 Findings unseres kommerziellen SAST sind real und wertvoll, und die Regeln dahinter wurden über mehr als ein Jahrzehnt produktiver Nutzung verfeinert. Auch die 152 Findings der KI-Pipeline sind real und betreffen Kategorien, die patternbasierte Analysen strukturell nicht erkennen können. Beide gehören in ein ernsthaftes Sicherheitsprogramm.
Das Update der OWASP Top 10:2025 mit seinem stärkeren Fokus auf Supply-Chain-Fehler, den Umgang mit Ausnahmebedingungen und unsicheres Design verstärkt diese Komplementarität zusätzlich. Genau diese neuen Kategorien sind jene Bereiche, in denen reasoning-basierte KI-Analyse den größten Mehrwert bietet und traditionelle Scanning-Ansätze am wenigsten effektiv sind.
Wie es weitergeht
Die Pipeline ist nicht abgeschlossen. Vier Wochen Betrieb markieren den Anfang und nicht das Ende dieser Arbeit. In den kommenden Quartalen planen wir:
- die Abdeckung auf weitere Repositories über die aktuellen 23 hinaus auszudehnen,
- einen dedizierten Agenten für OWASP-LLM-Top-10-Risiken hinzuzufügen (also für die Komponenten unserer Plattform, die Large Language Models integrieren)
- die Integration in unsere CI/CD-Prozesse zu vertiefen, sodass schnelle Scans Pull Requests blockieren und vollständige Scans auf Release-Branches ausgeführt werden und die Pipeline auf Opus 4.8 neu kalibrieren..
Wir betrachten KI-gestützte Sicherheit als dauerhafte Fähigkeit und nicht als einmalige Initiative und werden weiterhin in sie investieren, um Schwachstellenerkennung mit der Geschwindigkeit moderner Angriffe voranzutreiben.
Diese Arbeit wurde von Giuseppe Gottardi mit Unterstützung seines Cybersecurity-Teams sowie von Gabriele Mariotti, Identity Technical Manager, Trust Services & Technologies, für die Validierung der Schwachstellen durchgeführt.





