

Au cours des dernières semaines, trois annonces ont changé la conversation autour de l’intelligence artificielle et de la cybersécurité.
- Anthropic a annoncé le projet Glasswing, une initiative menée en collaboration avec AWS, Apple, Broadcom, Cisco, CrowdStrike, Google, JPMorgan Chase, la Linux Foundation, Microsoft, NVIDIA et Palo Alto Networks, et soutenue par cent millions de dollars de crédits d’utilisation, visant à appliquer Claude Mythos Preview aux logiciels les plus critiques au monde. Mythos Preview est le modèle de pointe le plus performant d’Anthropic, que la société a choisi de ne pas rendre public.
- Mozilla a utilisé ce même modèle pour identifier et corriger 271 vulnérabilités dans une seule version de Firefox.
- Cloudflare a publié un compte rendu détaillé de son utilisation sur plus de cinquante de ses propres référentiels de code.
Le message est sans ambiguïté : la découverte de vulnérabilités assistée par IA n’est plus expérimentale. C’est désormais une pratique défensive que les organisations sérieuses adoptent dès aujourd’hui.
Chez Namirial, nous avons commencé à élaborer notre réponse à ce défi la même semaine où Claude Opus 4.7 est devenu disponible en version générale, à la mi-avril 2026. Quatre semaines plus tard, nous disposons de résultats qui méritent d’être partagés.
Pourquoi cela est important pour un trust service provider
En tant que prestataire de services de confiance qualifiés (QTSP) au sens d’eIDAS, Namirial exploite des infrastructures que le cadre européen classe explicitement comme critiques. Chaque signature électronique que nous générons, chaque identité que nous vérifions, chaque horodatage que nous émettons fait partie du socle numérique sur lequel s’appuient chaque jour les administrations publiques, les banques, les assurances, les systèmes de santé et des millions de citoyens.
Ce rôle implique un niveau de responsabilité exceptionnel. Les exigences de sécurité applicables à un QTSP sont au moins aussi élevées que celles d’un fournisseur mondial de services cloud, et le cadre réglementaire, à travers eIDAS 2.0 et la directive Critical Entities Resilience, exige une démarche d’amélioration continue plutôt qu’une simple conformité ponctuelle.
Comme toute organisation d’ingénierie de notre taille, notre chaîne d’outils de sécurité comprend des solutions commerciales standard pour le SAST, l’analyse des dépendances, la détection de secrets ainsi qu’un processus structuré de revue de sécurité des mises en production. Ces outils remplissent parfaitement leur rôle : détecter un large éventail de vulnérabilités connues fondées sur des modèles identifiables, telles que les injections SQL, les identifiants exposés et les dépendances vulnérables.
Ce qu’ils ne détectent pas systématiquement, c’est la catégorie plus complexe : les défauts de logique métier, les chaînes d’exploitation multi-étapes, les usages cryptographiques incorrects et difficiles à détecter, les problèmes de conception et les vulnérabilités réparties sur plusieurs fichiers ou modules d’une manière que l’analyse fondée sur des modèles connus ne peut pas suivre. C’est précisément dans cette zone qu’un modèle d’IA basé sur le raisonnement – capable de lire le code, de comprendre son intention et de suivre les flux de données au-delà des limites entre fichiers et modules – apporte une valeur que les outils traditionnels ne peuvent structurellement pas offrir.
Le classement OWASP Top 10:2025, finalisé en janvier 2026, conserve la catégorie « Conception non sécurisée » (A06) et ajoute celle de « Mauvaise gestion des conditions exceptionnelles » (A10) parmi les catégories que l’analyse basée sur des modèles ne peut structurellement pas détecter. Ce sont précisément ces types de vulnérabilités pour lesquels l’analyse par IA basée sur le raisonnement apporte une valeur ajoutée que les outils traditionnels ne peuvent offrir.
Le modèle que nous avons utilisé
Claude Mythos Preview, le modèle de pointe le plus performant d’Anthropic, a été annoncé le 7 avril 2026 dans le cadre du projet Glasswing. Son accès a été restreint à un groupe limité de partenaires de la plateforme et n’est pas disponible au grand public. Neuf jours plus tard, le 16 avril 2026, Anthropic a rendu Opus 4.7 disponible de manière générale.
Opus 4.7 est le modèle que nous avons utilisé pour le pipeline décrit dans cet article. Ce n’est pas Mythos et contrairement à Mythos, il n’a pas démontré les mêmes capacités de pointe dans les tâches de sécurité. Il s’agit néanmoins du modèle d’Anthropic disponible de manière générale le plus performant au moment de la rédaction de ce texte, et nous voulions comprendre ce qu’il était possible d’accomplir avec lui sur des bases de code de production réelles.
Le pipeline s’exécute sur des modèles Claude hébergés dans des régions AWS européennes via Amazon Bedrock, selon des conditions commerciales garantissant que notre code n’est pas utilisé pour entraîner le modèle sous-jacent et n’est pas conservé au-delà de l’opération d’inférence. L’ensemble des données sources reste sous le contrôle de Namirial tout au long de l’analyse.
Note ajoutée lors de la publication : le 28 mai 2026, alors que cet article était en cours de finalisation, Anthropic a lancé Opus 4.8, son modèle le plus performant disponible au grand public. Les changements les plus pertinents pour ce travail ne concernent pas les capacités brutes. Opus 4.8 ferait moins d’affirmations non étayées et signalerait plus facilement ses propres incertitudes, ce qui a une incidence directe sur la phase de validation adversaire et le taux de faux positifs décrits ci-dessus ; de plus, sa nouvelle orchestration parallèle de sous-agents reflète la structure multi-agents sur laquelle repose déjà notre pipeline. Les résultats présentés dans cet article ont été obtenus avec Opus 4.7 ; la prochaine étape immédiate consiste à recalibrer le pipeline sur la version 4.8.
Ce que nous avons construit
Nous avons conçu un pipeline de sécurité assistée par IA qui exécute en parallèle neuf agents spécialisés sur nos bases de code, puis valide et consolide leurs résultats au travers de plusieurs étapes indépendantes de revue. Sans entrer dans des détails techniques trop poussés, l’architecture suit un principe vers lequel converge la communauté de la sécurité : séparer la détection rapide fondée sur des modèles connus, le raisonnement sémantique approfondi et la validation adversariale en étapes distinctes, plutôt que de s’appuyer sur un seul agent IA polyvalent.
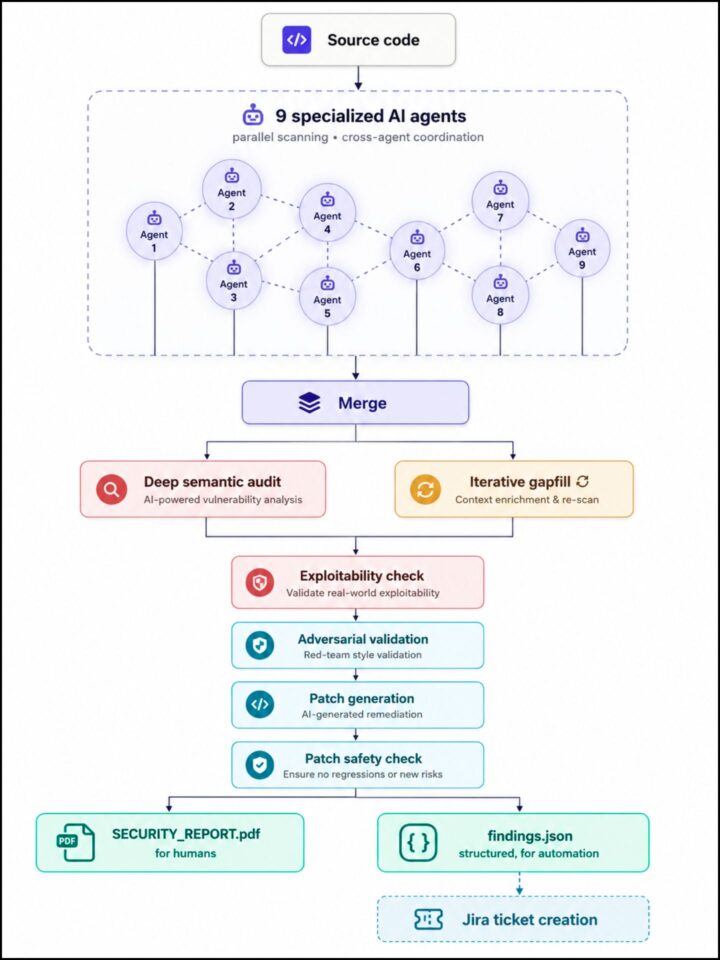
Le pipeline produit deux résultats : un rapport PDF lisible par les humains et un flux JSON structuré qui ouvre automatiquement des tickets dans notre système de gestion des tickets, en routant chaque vulnérabilité détectée vers l’équipe appropriée sans tri manuel. Cette séparation est plus importante qu’il n’y paraît. L’IA met en évidence les vulnérabilités, mais la réponse des équipes d’ingénierie reste ancrée dans notre processus de développement existant.
Cette architecture était très similaire aux approches documentées dans de récents articles de l’industrie. Cette convergence n’est pas une coïncidence : c’est l’approche que ce type de travail doit adopter pour être efficace. Cela suggère également que la variable la plus importante est l’architecture elle-même – la manière dont les agents sont orchestrés, validés et combinés – autant, sinon plus, que le modèle sous-jacent utilisé.
Ce que nous avons trouvé
Nous avons exécuté le pipeline sur 23 dépôts internes, totalisant environ 1,40 million de lignes de code. Le même périmètre a été analysé par notre solution commerciale de SAST. Tous les résultats ci-dessous ont été obtenus sur une période de quatre semaines, entre la mi-avril et la mi-mai 2026.
Les principaux résultats de la comparaison sont les suivants : sur l’ensemble du périmètre, notre outil SAST commercial a identifié 17 vulnérabilités de niveau élevé ou critique, qui ont toutes déjà été triées et corrigées dans le cadre de notre processus standard de gestion des vulnérabilités. Le pipeline d’IA a généré 152 vulnérabilités potentielles, dont 136 ont été confirmées par les responsables du code et par la suite corrigées, soit 8,0 fois plus que le résultat de référence du SAST.
En examinant les données dépôt par dépôt :
- Sur 22 des 23 dépôts, le pipeline IA a identifié davantage de vulnérabilités de niveau élevé ou critique que la solution commerciale de SAST.
- Sur 15 des 23 dépôts, la solution commerciale de SAST n’a signalé aucune vulnérabilité de niveau élevé ou critique, tandis que le pipeline IA a identifié entre 2 et 13 vulnérabilités confirmées pour chacun d’eux.
- Sur un dépôt, le SAST commercial a identifié légèrement plus de résultats que le pipeline d’IA (4 contre 3). C’est le seul cas de notre jeu de données dans lequel l’outil traditionnel a surpassé le pipeline IA, et l’écart n’est que d’une vulnérabilité.
- Les 17 vulnérabilités identifiées par la solution commerciale de SAST étaient concentrées sur seulement 8 des 23 dépôts.
Ce que le pipeline IA a détecté au-delà des capacités de l’analyse fondée sur des modèles connus
Parmi les 152 résultats potentiels mis en évidence par le pipeline IA, 70 (46 %) provenaient exclusivement de l’étape d’audit sémantique approfondi : des vulnérabilités identifiées par un agent capable de raisonner sur l’intention du code et sur les flux de données entre plusieurs fichiers, et non par une analyse fondée sur des modèles connus. C’est précisément dans cette catégorie que l’analyse IA apporte une valeur que les outils traditionnels ne peuvent structurellement pas fournir.
Les 82 vulnérabilités restantes provenaient des agents spécialisés exécutés en parallèle, couvrant les injections, la désérialisation, la cryptographie, les SSRF, les XXE, l’authentification, l’autorisation, les dépendances de la chaîne d’approvisionnement logicielle, l’infrastructure en tant que code et la gestion des exceptions.
Le tableau par catégories
Le point le plus important n’est pas le ratio de 8,9× pris isolément, mais la répartition des catégories de vulnérabilités. Sur les quinze dépôts déclarés exempts de vulnérabilités de niveau élevé ou critique par la solution commerciale de SAST, le pipeline IA a mis en évidence :
- Des défauts d’authentification et d’autorisation liés à des chaînes de responsabilité applicative difficiles à retracer
- Des implémentations cryptographiques reposant sur les bons algorithmes, mais utilisées de manière incorrecte
- Des violations de frontières de confiance où des données non fiables influencent des décisions de sécurité impliquant plusieurs fichiers
- Une gestion des exceptions en mode fail-open sur des chemins critiques
- Des schémas de conception non sécurisés, relevant par définition de la catégorie OWASP A06:2025
Les 17 vulnérabilités identifiées par la solution commerciale de SAST correspondaient précisément au type de défauts « classiques » pour lesquels la reconnaissance de modèles, soutenue par des règles affinées depuis plus d’une décennie, reste particulièrement efficace. Nous ne prétendons pas que l’outil commercial soit « défaillant » : il couvre extrêmement bien un périmètre limité de risques, mais n’adresse pas une catégorie beaucoup plus large de vulnérabilités.
Les deux approches sont complémentaires et non substituables. Notre feuille de route maintient la solution commerciale de SAST pour les catégories reposant fortement sur des modèles connus, où ses règles ont atteint un haut niveau de maturité, et utilise le pipeline IA pour les vulnérabilités qu’elle seule permet de révéler.
Deux chiffres que nous publions sans les enjoliver :
- L’étape de validation adversariale rejette environ 33 % des vulnérabilités potentielles. Avant qu’une vulnérabilité n’atteigne un analyste humain, un agent indépendant tente de la réfuter, agissant comme un relecteur sceptique plutôt que comme un détecteur. Environ un tiers des vulnérabilités initialement signalées ne survivent pas à cette étape et sont supprimées du rapport final. Les 152 vulnérabilités de niveau élevé ou critique mentionnées ci-dessus sont celles qui l’ont franchie. Nous considérons cette étape comme une fonctionnalité et non comme une faiblesse : sans elle, le taux de faux positifs visible pour les ingénieurs serait sensiblement plus élevé.
- Le périmètre comparé ici correspond au sous-ensemble de notre base de code sur lequel les deux outils ont été appliqués dans des conditions directement comparables. Notre SAST commercial couvre actuellement d’autres dépôts sur lesquels le pipeline IA n’a pas encore été exécuté. La comparaison est pertinente dans le périmètre considéré, mais ne constitue pas un audit complet de la plateforme.
Ce que cela signifie concrètement
Les quatre semaines passées à exécuter ce pipeline sur nos dépôts nous ont conduits à plusieurs conclusions pratiques.
L’analyse de sécurité IA multi-agents fonctionne, et fonctionne bien, lorsque l’architecture est correctement conçue. Le schéma qui se dégage de nos résultats, du rapport de Cloudflare et du travail de Mozilla sur Firefox est le même : détection parallèle spécialisée, audit sémantique approfondi, validation adversariale et restitution structurée des résultats. Un agent unique polyvalent produit des résultats nettement moins bons que cette approche en couches.
L’analyse assistée par IA complète les solutions SAST traditionnelles plutôt qu’elle ne les remplace. Les 17 vulnérabilités identifiées par notre solution commerciale de SAST sont réelles et précieuses, et les règles qui les sous-tendent ont été affinées au fil de plus d’une décennie d’utilisation en production. Les 152 vulnérabilités révélées par le pipeline IA sont elles aussi réelles et couvrent des catégories que l’analyse fondée sur des modèles connus ne peut structurellement pas détecter. Les deux ont leur place dans un programme de sécurité sérieux.
La mise à jour OWASP Top 10:2025, avec son nouvel accent sur les défaillances de la chaîne d’approvisionnement logicielle, la gestion des conditions exceptionnelles et la conception non sécurisée, renforce encore cette complémentarité. Les nouvelles catégories sont précisément celles où l’analyse IA fondée sur le raisonnement apporte le plus de valeur et où les outils traditionnels sont les moins efficaces.
La suite
Le pipeline n’est pas terminé. Quatre semaines d’exploitation représentent le début et non l’aboutissement de ce travail. Au cours des prochains trimestres, nous prévoyons de:
- étendre la couverture à d’autres dépôts au-delà des 23 actuels,
- ajouter un agent dédié aux risques du classement OWASP LLM Top 10 (pour les composants de notre plateforme intégrant des grands modèles de langage)
- renforcer l’intégration avec notre CI/CD afin que des analyses rapides bloquent les demandes de fusion et que des analyses complètes soient exécutées sur les branches de mise en production, et réinitialiser la base de référence du pipeline sur Opus 4.8.
Nous considérons la sécurité assistée par IA comme une capacité permanente et non comme une initiative ponctuelle, et nous continuerons à y investir afin d’accélérer la détection des vulnérabilités au rythme des attaques modernes.
Ce travail a été réalisé par Giuseppe Gottardi avec le soutien de son équipe de cybersécurité, ainsi que par Gabriele Mariotti, Identity Technical Manager, Trust Services & Technologies, pour la validation des vulnérabilités.





