

Nas últimas semanas, três anúncios mudaram a conversa em torno da inteligência artificial e da cibersegurança.
- A Anthropic anunciou o Projeto Glasswing, uma iniciativa coordenada com a AWS, Apple, Broadcom, Cisco, CrowdStrike, Google, JPMorgan Chase, a Linux Foundation, Microsoft, NVIDIA e Palo Alto Networks, apoiada por cem milhões de dólares em créditos de uso, com o objetivo de aplicar o Claude Mythos Preview aos softwares mais críticos do mundo. O Mythos Preview é o modelo de ponta mais avançado da Anthropic, que a empresa optou por não divulgar publicamente.
- A Mozilla utilizou o mesmo modelo para identificar e corrigir 271 vulnerabilidades em uma única versão do Firefox.
- A Cloudflare publicou um relato detalhado sobre sua execução em mais de cinquenta de seus próprios repositórios de código.
A mensagem é inequívoca: a descoberta de vulnerabilidades assistida por IA não é mais experimental. Trata-se de uma prática defensiva que organizações sérias já estão adotando agora.
Na Namirial, começamos a construir nossa resposta a esse desafio na mesma semana em que o Claude Opus 4.7 se tornou amplamente disponível, em meados de abril de 2026. Quatro semanas depois, temos resultados que valem a pena compartilhar.
Por que isso importa para um trust service provider
Como Qualified Trust Service Provider sob o eIDAS, a Namirial opera infraestruturas que o framework europeu classifica explicitamente como críticas. Cada assinatura eletrônica que geramos, cada identidade que verificamos, cada carimbo do tempo que emitimos faz parte da espinha dorsal digital da qual administrações públicas, bancos, seguradoras, sistemas de saúde e milhões de cidadãos dependem todos os dias.
Essa posição traz um padrão incomum de responsabilidade. As expectativas de segurança impostas a um QTSP são pelo menos tão elevadas quanto aquelas direcionadas a um provedor global de nuvem, e o arcabouço regulatório, por meio do eIDAS 2.0 e da diretiva Critical Entities Resilience, exige melhoria contínua e não apenas conformidade pontual.
Como qualquer organização de engenharia do nosso porte, nossa cadeia de ferramentas de segurança inclui soluções comerciais padrão de mercado para SAST, varredura de dependências, detecção de segredos e um processo estruturado de revisão de segurança para releases. Essas ferramentas funcionam bem para aquilo para o qual foram projetadas: identificar a longa cauda de defeitos baseados em padrões conhecidos, como SQL injection, credenciais expostas e dependências vulneráveis.
O que elas consistentemente não conseguem detectar é a categoria mais complexa: falhas de lógica de negócio, cadeias de exploração em múltiplas etapas, usos sutis e incorretos de criptografia, problemas de design e vulnerabilidades distribuídas entre múltiplos arquivos ou módulos de maneiras que análises baseadas em padrões não conseguem rastrear. É exatamente nessa lacuna que um modelo de IA baseado em reasoning – capaz de ler código, entender intenções e seguir fluxos de dados através de fronteiras – agrega um valor que ferramentas tradicionais, estruturalmente, não conseguem oferecer.
O OWASP Top 10:2025, finalizado em janeiro de 2026, mantém o “Design Inseguro” (A06) e acrescenta o “Tratamento Incorreto de Condições Excepcionais” (A10) como categorias que a análise baseada em padrões não consegue detectar estruturalmente. Essas são exatamente as classes de resultados em que a análise de IA baseada em raciocínio agrega valor que as ferramentas tradicionais não oferecem.
O modelo que utilizamos
O Claude Mythos Preview, o modelo de ponta mais avançado da Anthropic, foi anunciado em 7 de abril de 2026 no âmbito do Projeto Glasswing. O acesso foi restrito a um grupo limitado de parceiros de plataforma e não está disponível ao público em geral. Nove dias depois, em 16 de abril de 2026, a Anthropic tornou o Opus 4.7 amplamente disponível.
O Opus 4.7 é o modelo que utilizamos para a pipeline descrita neste artigo. Ele não é o Mythos e, ao contrário do Mythos, ele não demonstrou o mesmo nível de capacidade de ponta em tarefas de segurança. No entanto, é o modelo mais poderoso da Anthropic disponível publicamente no momento da redação deste texto, e queríamos entender o que poderia ser alcançado com ele em codebases reais de produção.
O pipeline é executado em modelos Claude hospedados em regiões europeias da AWS por meio do Amazon Bedrock, sob termos comerciais que garantem que nosso código não seja usado para treinar o modelo subjacente e não seja retido após a operação de inferência. Todo o material de origem permanece sob o controle da Namirial durante toda a análise.
Nota adicionada na publicação: em 28 de maio de 2026, enquanto este artigo estava sendo finalizado, a Anthropic lançou o Opus 4.8 como seu modelo de uso geral mais avançado. As mudanças mais relevantes para este trabalho não dizem respeito à capacidade bruta. Relata-se que o Opus 4.8 faz menos afirmações sem fundamento e sinaliza sua própria incerteza com mais facilidade, o que tem impacto direto na etapa de validação adversária e na taxa de falsos positivos descritas acima, e sua nova orquestração paralela de subagentes reflete a estrutura multiagente na qual nosso pipeline já se baseia. Os resultados apresentados neste post foram produzidos no Opus 4.7; redefinir a linha de base do pipeline para a versão 4.8 é nosso próximo passo imediato.
O que construímos
Projetamos uma pipeline de segurança assistida por IA que executa nove agentes especializados em paralelo sobre nossas bases de código e depois valida e consolida seus resultados por meio de diversas etapas independentes de revisão. Sem entrar em detalhes excessivamente técnicos, a arquitetura segue um princípio para o qual a comunidade de segurança está convergindo: separar detecção rápida baseada em padrões, reasoning semântico profundo e validação adversarial como etapas distintas, em vez de depender de um único agente de IA generalista.
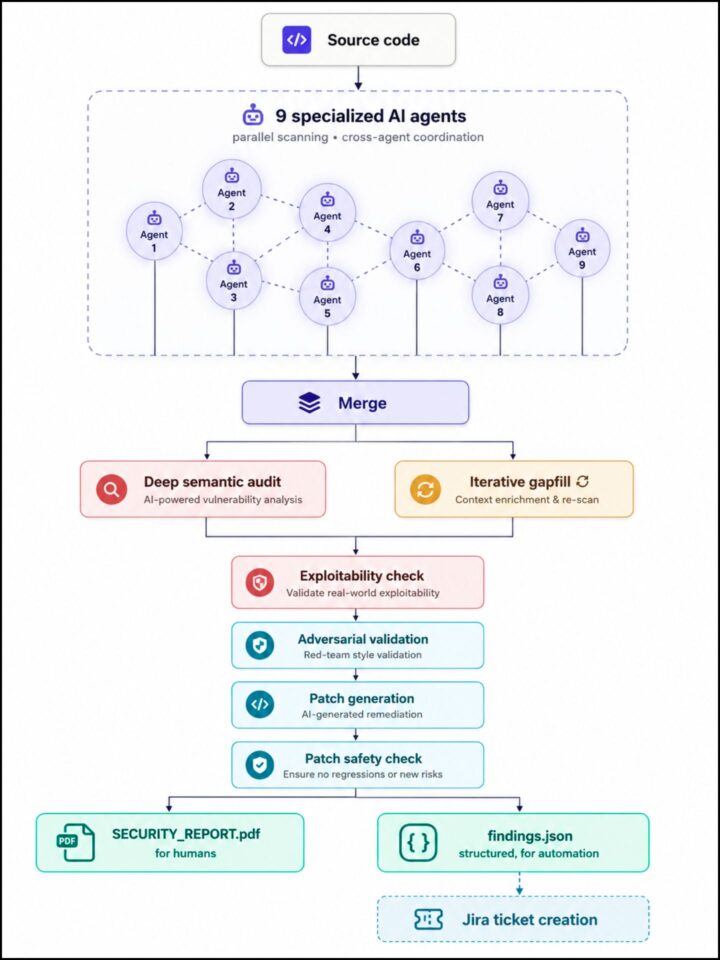
A pipeline produz dois outputs: um relatório PDF legível por humanos e um feed JSON estruturado que abre automaticamente tickets em nosso issue tracker, direcionando cada finding para a equipe correta sem necessidade de triagem manual. Essa separação é mais importante do que parece. A IA identifica vulnerabilidades, mas a resposta de engenharia permanece ancorada em nosso workflow de desenvolvimento já existente.
A arquitetura é surpreendentemente semelhante às abordagens documentadas em análises recentes da indústria sobre o tema. A convergência não é coincidência: essa é a forma que esse trabalho precisa assumir para ser eficaz. Isso também sugere que a variável mais importante aqui é a arquitetura em si — como os agentes são orquestrados, validados e compostos — pelo menos tanto quanto o modelo subjacente específico.
O que encontramos
Executamos a pipeline em 23 repositórios internos, totalizando aproximadamente 1,40 milhão de linhas de código. O mesmo perímetro foi analisado pela nossa plataforma comercial de SAST. Todos os resultados abaixo foram produzidos em uma janela de quatro semanas, entre meados de abril e meados de maio de 2026.
A principal comparação é a seguinte: em todo o perímetro, nossa SAST comercial identificou 17 resultados de alto risco ou críticos, todos já triados e resolvidos por meio de nosso processo padrão de gerenciamento de vulnerabilidades. O pipeline de IA produziu 152 resultados potenciais, dos quais 136 foram confirmados pelos responsáveis pelo código e, posteriormente, corrigidos, ou seja, 8,0 vezes mais do que a linha de base da SAST.
Observando os dados repositório por repositório:
- Em 22 dos 23 repositórios, a pipeline de IA identificou mais findings high ou critical do que o SAST comercial.
- Em 15 dos 23 repositórios, o SAST comercial reportou zero findings high ou critical, enquanto a pipeline de IA identificou entre 2 e 13 findings confirmados em cada um.
- Em um repositório, o SAST comercial identificou um número ligeiramente maior de achados do que o pipeline de IA (4 contra 3). É o único caso em nosso dataset em que a ferramenta tradicional superou a pipeline de IA, e a diferença é de apenas um finding..
- Os 17 findings do SAST comercial estavam concentrados em apenas 8 dos 23 repositórios.
O que a pipeline de IA encontrou e que a análise baseada em padrões não conseguiu detectar
Entre os 152 achados candidatos identificados pela pipeline de IA, 70 (46%) vieram exclusivamente da etapa de auditoria semântica profunda: vulnerabilidades identificadas por um agente que raciocina sobre a intenção do código e o fluxo de dados entre arquivos, e não por pattern matching. Essa é a categoria em que a análise de IA agrega um valor que ferramentas tradicionais, estruturalmente, não conseguem oferecer.
Os 82 findings restantes vieram dos agentes paralelos especializados em injection, desserialização, criptografia, SSRF, XXE, autenticação, autorização, dependências de supply chain, infrastructure-as-code e exception handling.
A visão categórica
A conclusão mais importante não é o índice de 8,9× isoladamente, mas a distribuição por categorias. Nos quinze repositórios em que o SAST comercial reportou “clean”, a pipeline de IA identificou:
- Defeitos de autenticação e autorização com cadeias de ownership não óbvias
- Operações criptográficas utilizando o algoritmo correto da maneira errada
- Violações de trust boundaries onde dados não confiáveis influenciam decisões de segurança entre arquivos
- Exception handling fail-open em caminhos críticos
- Padrões de design inseguros: toda a categoria OWASP A06:2025 por definição
Os 17 findings identificados pelo SAST comercial eram exatamente o tipo de defeito “clássico” em que o pattern matching, apoiado por regras refinadas ao longo de mais de uma década, continua genuinamente forte. Não estamos argumentando que a ferramenta comercial esteja “quebrada”: ela cobre extremamente bem uma faixa estreita de risco e não cobre de forma alguma uma faixa muito mais ampla.
As duas abordagens são complementares, e não substitutas. Nossa roadmap mantém o SAST comercial para categorias ricas em padrões, onde suas regras são maduras, e utiliza a pipeline de IA para aquilo que somente ela consegue revelar.
Dois números que publicamos sem tentar suavizá-los:
- A etapa de validação adversarial rejeita aproximadamente 33% dos findings candidatos. Antes que qualquer finding chegue a um revisor humano, um agente independente tenta refutá-lo, agindo mais como um peer reviewer cético do que como um identificador de vulnerabilidades. Cerca de um terço dos candidatos inicialmente sinalizados não sobrevive a essa etapa e é removido do relatório final. Os 152 findings high/critical citados acima são aqueles que sobreviveram. Consideramos essa etapa uma característica positiva, e não um constrangimento: sem ela, a taxa de falsos positivos visível para os engenheiros seria substancialmente maior.
- O perímetro comparado aqui é o subconjunto de nossa base de código em que ambas as ferramentas foram aplicadas em condições diretamente comparáveis. Nosso SAST comercial atualmente cobre repositórios adicionais nos quais a pipeline de IA ainda não foi executada. A comparação é significativa dentro de seu escopo, mas não representa uma auditoria completa da plataforma.
O que isso significa na prática
As quatro semanas que passamos executando essa pipeline sobre nossos repositórios nos deixaram algumas conclusões práticas.
A análise de segurança com IA multiagente funciona – e funciona bem – quando a arquitetura é corretamente projetada. O padrão que emerge de nossos resultados, do relatório da Cloudflare e do trabalho da Mozilla com o Firefox é o mesmo: detecção paralela especializada, auditoria semântica profunda, validação adversarial e relatórios estruturados. Um único agente generalista produz resultados perceptivelmente inferiores a essa abordagem em camadas.
A tecnologia complementa, em vez de substituir, o SAST tradicional. Os 17 findings identificados pelo nosso SAST comercial são reais e valiosos, e as regras por trás deles foram refinadas ao longo de mais de uma década de uso em produção. Os 152 findings revelados pela pipeline de IA também são reais e cobrem categorias que análises baseadas em padrões, estruturalmente, não conseguem detectar. Ambos pertencem a um programa de segurança sério.
A atualização do OWASP Top 10:2025, com sua nova ênfase em falhas de supply chain, tratamento de condições excepcionais e insecure design, reforça essa complementaridade. As novas categorias são precisamente aquelas em que análises de IA baseadas em reasoning agregam mais valor e onde o scanning tradicional é menos eficaz.
O que vem a seguir
A pipeline não está concluída. Quatro semanas de operação representam o começo, e não a conclusão desse trabalho. Nos próximos trimestres planejamos:
- expandir a cobertura para repositórios adicionais além dos atuais 23;
- adicionar um agente dedicado aos riscos OWASP LLM Top 10 (para os componentes da nossa plataforma que integram large language models)
- aprofundar a integração com nosso CI/CD para que varreduras rápidas bloqueiem pull requests e varreduras completas sejam executadas em release branches, e redefinir a linha de base do pipeline para o Opus 4.8.
Enxergamos a segurança assistida por IA como uma capacidade permanente, e não como uma iniciativa pontual, e continuaremos investindo nela para impulsionar a detecção de vulnerabilidades na velocidade dos ataques modernos.
Este trabalho foi realizado por Giuseppe Gottardi com o apoio de sua equipe de cibersegurança e por Gabriele Mariotti, Identity Technical Manager, Trust Services & Technologies, responsável pela validação das vulnerabilidades.





