

Nelle ultime settimane, tre annunci hanno cambiato il modo di parlare di AI e cybersecurity.
- Anthropic ha annunciato Project Glasswing, un’iniziativa coordinata con AWS, Apple, Broadcom, Cisco, CrowdStrike, Google, JPMorgan Chase, la Linux Foundation, Microsoft, NVIDIA e Palo Alto Networks, sostenuta da cento milioni di dollari in crediti di utilizzo, volta ad applicare Claude Mythos Preview ai software più critici al mondo. Mythos Preview è il modello all’avanguardia più potente di Anthropic, che l’azienda ha deciso di non rendere pubblico.
- Mozilla ha usato lo stesso modello per identificare e correggere 271 vulnerabilità in una singola versione di Firefox.
- Cloudflare ha pubblicato un resoconto dettagliato della sua applicazione su più di cinquanta dei propri repository di codice.
Il messaggio è inequivocabile: l’identificazione delle vulnerabilità assistita dall’AI non è più sperimentale. È una pratica difensiva che le organizzazioni serie stanno adottando ora.
In Namirial abbiamo iniziato a costruire la nostra risposta a questa sfida la stessa settimana in cui Claude Opus 4.7 è diventato generalmente disponibile, a metà aprile 2026. Quattro settimane dopo, abbiamo risultati che vale la pena condividere.
Perché questo è importante per un trust service provider
Come Qualified Trust Service Provider ai sensi di eIDAS, Namirial gestisce infrastrutture che il quadro normativo europeo classifica esplicitamente come critiche. Ogni firma elettronica che generiamo, ogni identità che verifichiamo, ogni marca temporale che emettiamo fa parte della spina dorsale digitale su cui ogni giorno fanno affidamento pubbliche amministrazioni, banche, assicurazioni, sistemi sanitari e milioni di cittadini.
Questa posizione comporta un livello di responsabilità fuori dal comune. Le aspettative di sicurezza poste su un QTSP sono almeno pari a quelle di un cloud provider globale, e il quadro normativo, attraverso eIDAS 2.0 e la direttiva CER (Critical Entities Resilience), richiede un miglioramento continuo, non una conformità limitata a un dato momento nel tempo.
Come ogni organizzazione ingegneristica delle nostre dimensioni, il nostro toolchain di sicurezza include strumenti commerciali standard di settore per SAST, dependency scanning, rilevamento di secret e un processo strutturato di security review per le release. Questi strumenti funzionano bene per ciò per cui sono progettati: intercettare la lunga coda di difetti noti e riconoscibili tramite pattern, come SQL injection, credenziali esposte e dipendenze vulnerabili.
Ciò che sistematicamente non riescono a rilevare è la categoria più complessa: vulnerabilità di business logic, catene di exploit multi-step, utilizzi impropri e sottili della crittografia, problemi architetturali e vulnerabilità distribuite su più file o moduli in modi che l’analisi basata su pattern non riesce a tracciare. È precisamente questo il gap in cui un modello AI basato sul ragionamento – capace di leggere il codice, comprenderne l’intento e seguire i flussi di dati oltre i confini dei moduli – aggiunge un valore che gli strumenti tradizionali strutturalmente non possono offrire.
La classifica OWASP Top 10:2025, definita nel gennaio 2026, mantiene la voce “Progettazione non sicura” (A06) e aggiunge quella relativa alla “Gestione errata delle condizioni eccezionali” (A10) tra le categorie che l’analisi basata su modelli non è strutturalmente in grado di rilevare. Si tratta proprio delle tipologie di risultati in cui l’analisi basata sull’intelligenza artificiale (AI) aggiunge un valore che gli strumenti tradizionali non sono in grado di fornire.
Il modello che abbiamo usato
Claude Mythos Preview, il modello di frontiera più potente di Anthropic, è stato annunciato il 7 aprile 2026 nell’ambito del Progetto Glasswing. L’accesso è stato limitato a un gruppo ristretto di partner della piattaforma e non è disponibile al pubblico. Nove giorni dopo, il 16 aprile 2026, Anthropic ha reso generalmente disponibile Opus 4.7.
Opus 4.7 è il modello che abbiamo usato per la pipeline descritta in questo articolo. Non è Mythos e, a differenza di Mythos, non ha dimostrato la stessa capacità all’avanguardia nelle attività di sicurezza. È però il modello generalmente disponibile più avanzato di Anthropic al momento della stesura di questo testo, e volevamo capire cosa fosse possibile ottenere con esso su codebase di produzione reali.
La pipeline funziona su modelli Claude ospitati nelle regioni europee di AWS tramite Amazon Bedrock, secondo condizioni commerciali che garantiscono che il nostro codice non venga utilizzato per addestrare il modello sottostante e non venga conservato oltre l’operazione di inferenza. Tutto il materiale di partenza rimane sotto il controllo di Namirial per tutta la durata dell’analisi.
Nota aggiunta al momento della pubblicazione: il 28 maggio 2026, mentre questo articolo veniva finalizzato, Anthropic ha rilasciato Opus 4.8 come suo modello più potente disponibile al pubblico. I cambiamenti più rilevanti per questo lavoro non riguardano la potenza pura. Opus 4.8 sembra fare meno affermazioni non supportate e segnalare più prontamente la propria incertezza, il che ha un impatto diretto sulla fase di validazione avversaria e sul tasso di falsi positivi descritti sopra, e la sua nuova orchestrazione parallela dei sub-agenti rispecchia la struttura multi-agente su cui si basa già la nostra pipeline. I risultati in questo post sono stati prodotti su Opus 4.7; il prossimo passo immediato è ridefinire la baseline della pipeline su 4.8.
Cosa abbiamo costruito
Abbiamo progettato una pipeline di sicurezza assistita dall’AI che esegue in parallelo nove agenti specializzati sui nostri codebase, validando e consolidando poi i risultati attraverso diversi livelli indipendenti di revisione. Senza entrare nei dettagli ingegneristici, l’architettura segue un principio verso cui la comunità della sicurezza sta convergendo: separare il rilevamento rapido basato su pattern, il ragionamento semantico profondo e la validazione avversariale in fasi distinte, invece di affidarsi a un singolo agente AI general purpose.
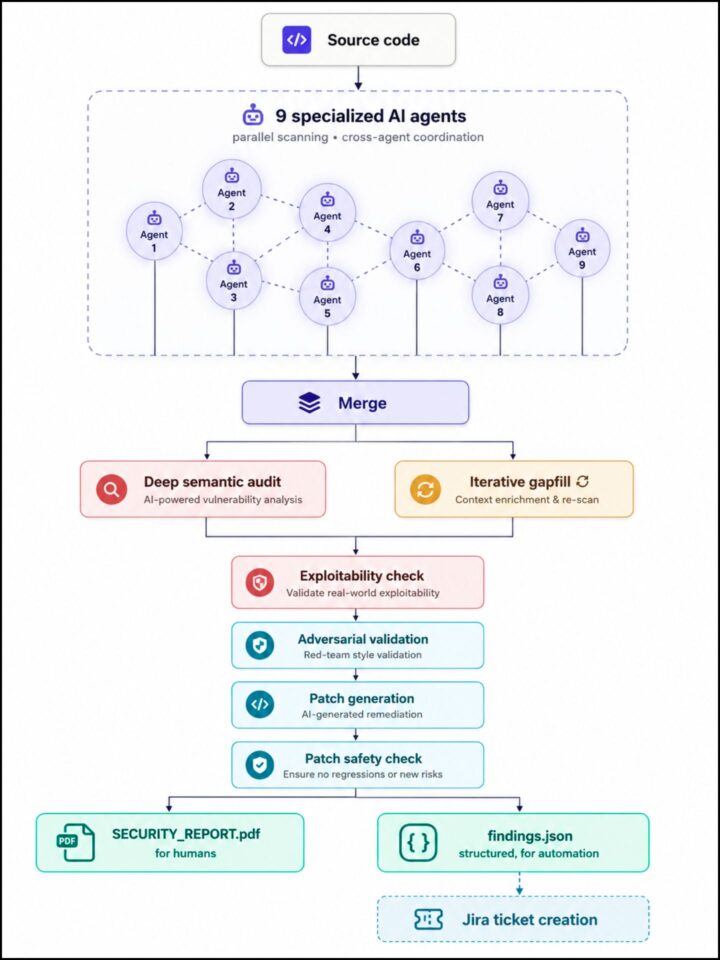
La pipeline produce due output: un report PDF leggibile dagli esseri umani e un feed JSON strutturato che apre automaticamente ticket nel nostro issue tracker, assegnando ogni vulnerabilità al team corretto, senza necessità di triage manuale. Questa separazione è più importante di quanto sembri. L’AI individua le vulnerabilità, ma la risposta ingegneristica rimane ancorata al nostro workflow di sviluppo esistente.
L’architettura è sorprendentemente simile agli approcci documentati nei recenti approfondimenti di settore sul tema. La convergenza non è casuale: è questa la forma che questo tipo di lavoro deve assumere per essere efficace. Questo suggerisce anche che la variabile più importante sia l’architettura – come gli agenti vengono orchestrati, validati e composti – almeno quanto il modello sottostante specifico.
Cosa abbiamo trovato
Abbiamo eseguito la pipeline su 23 repository interni, per un totale di circa 1,4 milioni di linee di codice. Lo stesso perimetro è stato analizzato anche dalla nostra piattaforma commerciale SAST. Tutti i risultati riportati sotto sono stati prodotti in un intervallo di quattro settimane, tra metà aprile e metà maggio 2026.
Il confronto principale: a livello perimetrale, il nostro SAST commerciale ha identificato 17 risultati di livello elevato o critico, tutti già sottoposti a triage e risolti attraverso il nostro processo standard di gestione delle vulnerabilità. La pipeline di IA ha prodotto 152 risultati candidati, di cui 136 sono stati confermati dai proprietari del codice e successivamente corretti, ovvero 8,0 volte di più rispetto alla linea di base SAST.
Osservando i dati repository per repository:
- In 22 repository su 23, la pipeline AI ha identificato più vulnerabilità high o critical rispetto al SAST commerciale.
- In 15 repository su 23, il SAST commerciale non ha riportato alcuna vulnerabilità high o critical, mentre la pipeline AI ha identificato tra 2 e 13 vulnerabilità confermate per ciascun repository.
- In 1 repository, il SAST commerciale ha identificato un numero leggermente superiore di risultati rispetto alla pipeline di IA (4 contro 3). Questo è l’unico caso nel nostro dataset in cui lo strumento tradizionale ha superato la pipeline AI, e il divario è di una sola vulnerabilità.
- Le 17 vulnerabilità individuate dal SAST commerciale erano concentrate in appena 8 dei 23 repository.
Cosa ha trovato la pipeline AI che l’analisi basata su pattern non poteva rilevare
Tra i 152 risultati candidati emersi dalla pipeline AI, 70 (46%) provenivano esclusivamente dalla fase di deep semantic audit: vulnerabilità identificate da un agente capace di ragionare sull’intento del codice e sui flussi di dati cross-file, non tramite pattern matching. È questa la categoria in cui l’analisi AI aggiunge un valore che gli strumenti tradizionali strutturalmente non possono offrire.
Le restanti 82 vulnerabilità provenivano dagli agenti specializzati paralleli che coprivano injection, deserializzazione, crittografia, SSRF, XXE, autenticazione, autorizzazione, supply chain dependencies, infrastructure-as-code ed exception handling.
Il quadro categoriale
L’aspetto più importante non è il rapporto 8,9× preso isolatamente, ma la distribuzione per categoria. Nei quindici repository in cui il SAST commerciale risultava “pulito”, la pipeline AI ha individuato:
- Difetti di autenticazione e autorizzazione con catene di ownership non ovvie
- Operazioni crittografiche che usavano l’algoritmo corretto nel modo sbagliato
- Violazioni dei trust boundary in cui dati non affidabili influenzavano decisioni di sicurezza attraverso più file
- Exception handling fail-open su percorsi critici
- Pattern di progettazione insicuri: l’intera categoria OWASP A06:2025 per definizione
Le 17 vulnerabilità individuate dal SAST commerciale erano precisamente il tipo di difetto “da manuale” in cui il pattern matching, affinato da regole evolute in dieci anni di uso in produzione, continua a essere realmente efficace. Non stiamo sostenendo che lo strumento commerciale sia “rotto”: copre molto bene una ristretta fascia di rischio e non copre affatto una fascia molto più ampia.
I due approcci sono complementari, non sostitutivi. La nostra roadmap mantiene il SAST commerciale per le categorie ricche di pattern, in cui le sue regole sono mature, e usa la pipeline AI per ciò che solo essa riesce a portare alla luce.
Due numeri che pubblichiamo senza edulcorarli:
- La fase di validazione avversariale scarta circa il 33% delle vulnerabilità candidate. Prima che una vulnerabilità raggiunga un revisore umano, un agente indipendente tenta di smentirla, agendo come un revisore scettico piuttosto che come un rilevatore. Circa un terzo delle vulnerabilità inizialmente segnalate non supera questa fase e viene escluso dal report finale. Le 152 vulnerabilità high/critical citate sopra sono quelle che invece l’hanno superata. Consideriamo questa fase una funzionalità, non un imbarazzo: senza di essa, il tasso di falsi positivi visibile agli ingegneri sarebbe significativamente più elevato.
- Il perimetro confrontato qui è il sottoinsieme del nostro codebase in cui entrambi gli strumenti sono stati applicati in condizioni direttamente comparabili. Il nostro SAST commerciale copre attualmente ulteriori repository sui quali la pipeline AI non è ancora stata eseguita. Il confronto è significativo all’interno del suo perimetro, ma non rappresenta un audit completo dell’intera piattaforma.
Cosa significa concretamente
Le quattro settimane trascorse eseguendo questa pipeline sui nostri repository ci hanno portato ad alcune conclusioni pratiche.
L’analisi di sicurezza AI multi-agente funziona, e funziona bene, quando l’architettura è progettata correttamente. Il pattern che emerge dai nostri risultati, dal resoconto di Cloudflare e dal lavoro di Mozilla su Firefox è lo stesso: rilevamento parallelo specializzato, deep semantic audit, validazione avversariale, reporting strutturato. Un singolo agente general purpose produce risultati sensibilmente peggiori rispetto a questo approccio stratificato.
La tecnologia integra, anziché sostituire, il SAST tradizionale. Le 17 vulnerabilità individuate dal nostro SAST commerciale sono reali e preziose, e le regole che le identificano sono state perfezionate in un decennio di uso in produzione. Anche le 152 vulnerabilità individuate dalla pipeline AI sono reali e coprono categorie che l’analisi basata su pattern non può intercettare per motivi strutturali. Entrambe appartengono a un programma di sicurezza serio.
L’aggiornamento della OWASP Top 10:2025, con il suo nuovo focus su supply chain failures, exceptional condition handling e insecure design, rafforza questa complementarità. Le nuove categorie sono precisamente quelle in cui l’analisi AI basata sul ragionamento aggiunge il massimo valore e in cui lo scanning tradizionale è meno efficace.
Cosa succederà ora
La pipeline non è conclusa. Quattro settimane di operatività rappresentano l’inizio, non la conclusione di questo lavoro. Nei prossimi trimestri prevediamo di:
- estendere la copertura ad altri repository oltre agli attuali 23;
- aggiungere un agente dedicato ai rischi OWASP LLM Top 10 (per i componenti della nostra piattaforma che integrano large language model);
- rafforzare l’integrazione con il nostro CI/CD affinché gli scan rapidi blocchino le pull request e gli scan completi vengano eseguiti sui release branch, e ridefinire la baseline della pipeline su Opus 4.8.
Consideriamo la sicurezza assistita dall’AI una capability permanente, non un’iniziativa una tantum, e continueremo a investirvi per accelerare il rilevamento delle vulnerabilità alla velocità degli attacchi moderni.
Questo lavoro è stato svolto da Giuseppe Gottardi con il supporto del suo team di cybersecurity e da Gabriele Mariotti, Identity Technical Manager, Trust Services & Technologies, per la validazione delle vulnerabilità.





