

În ultimele săptămâni, trei anunțuri au schimbat conversația despre inteligența artificială și securitatea cibernetică.
- Anthropic a anunțat Proiectul Glasswing, o inițiativă coordonată împreună cu AWS, Apple, Broadcom, Cisco, CrowdStrike, Google, JPMorgan Chase, Fundația Linux, Microsoft, NVIDIA și Palo Alto Networks, susținută de credite de utilizare în valoare de o sută de milioane de dolari, cu scopul de a aplica modelul Claude Mythos Preview celor mai critice programe software din lume. Mythos Preview este cel mai performant model de ultimă generație al Anthropic, pe care compania a decis să nu îl lanseze public.
- Mozilla a folosit același model pentru a identifica și remedia 271 de vulnerabilități într-o singură versiune de Firefox.
- Cloudflare a publicat un relatare detaliată privind rularea acestuia pe mai mult de cincizeci dintre propriile sale depozite de cod.
Mesajul este clar: descoperirea vulnerabilităților asistată de AI nu mai este experimentală. Este o practică defensivă pe care organizațiile serioase o adoptă deja acum.
La Namirial, am început să construim răspunsul nostru la această provocare în aceeași săptămână în care Claude Opus 4.7 a devenit disponibil în mod general, la mijlocul lunii aprilie 2026. Patru săptămâni mai târziu, avem rezultate care merită împărtășite.
De ce este important acest lucru pentru un trust service provider
În calitate de Qualified Trust Service Provider conform eIDAS, Namirial operează infrastructuri pe care cadrul european le clasifică explicit drept critice. Fiecare semnătură electronică pe care o generăm, fiecare identitate pe care o verificăm, fiecare marcă temporală pe care o emitem face parte din coloana vertebrală digitală pe care administrațiile publice, băncile, companiile de asigurări, sistemele medicale și milioane de cetățeni se bazează în fiecare zi.
Această poziție implică un standard neobișnuit de responsabilitate. Cerințele de securitate impuse unui QTSP sunt cel puțin la fel de ridicate precum cele impuse unui furnizor global de cloud, iar cadrul de reglementare, prin eIDAS 2.0 și directiva Critical Entities Resilience, solicită îmbunătățire continuă și nu doar conformitate punctuală.
Ca orice organizație de inginerie de dimensiunea noastră, lanțul nostru de instrumente de securitate include soluții comerciale standard din industrie pentru SAST, scanarea dependențelor, detectarea secretelor și un proces structurat de revizuire a securității pentru release-uri. Aceste instrumente funcționează foarte bine pentru ceea ce au fost concepute: identificarea defectelor bazate pe pattern-uri cunoscute, precum SQL injection, credențiale expuse și dependențe vulnerabile.
Ceea ce nu reușesc să detecteze în mod constant este categoria mai dificilă: defecte de logică de business, lanțuri de exploit multi-step, utilizări criptografice subtile și greșite, probleme de design și vulnerabilități care se extind pe mai multe fișiere sau module în moduri pe care analiza bazată pe pattern-uri nu le poate urmări. Exact în acest gol un model AI bazat pe reasoning – capabil să citească codul, să înțeleagă intenția și să urmărească fluxurile de date peste limite diferite – adaugă o valoare pe care instrumentele tradiționale, structural, nu o pot oferi.
Lista OWASP Top 10:2025, finalizată în ianuarie 2026, păstrează categoria „Proiectare nesigură” (A06) și adaugă categoria „Gestionarea necorespunzătoare a condițiilor excepționale” (A10) ca tipuri de vulnerabilități pe care analiza bazată pe modele nu le poate detecta din punct de vedere structural. Acestea sunt exact tipurile de vulnerabilități în cazul cărora analiza bazată pe raționament a IA aduce o valoare adăugată pe care instrumentele tradiționale nu o oferă.
Modelul pe care l-am folosit
Claude Mythos Preview, cel mai performant model de frontieră al Anthropic, a fost anunțat pe 7 aprilie 2026 în cadrul proiectului Glasswing. Accesul a fost restricționat la un grup limitat de parteneri ai platformei și nu este disponibil publicului larg. Nouă zile mai târziu, pe 16 aprilie 2026, Anthropic a făcut Opus 4.7 disponibil în mod general.
Opus 4.7 este modelul pe care l-am utilizat pentru pipeline-ul descris în acest articol. Nu este Mythos și, spre deosebire de Mythos, nu a demonstrat aceeași capacitate de vârf în ceea ce privește sarcinile de securitate. Este însă cel mai capabil model disponibil public de la Anthropic la momentul redactării acestui text și am dorit să înțelegem ce poate fi realizat cu el pe baze de cod reale, aflate în producție.
Pipeline-ul rulează pe modele Claude găzduite în regiunile AWS din Europa prin intermediul Amazon Bedrock, în condiții comerciale care garantează că codul nostru nu este utilizat pentru antrenarea modelului de bază și nu este păstrat după finalizarea operațiunii de inferență. Tot materialul sursă rămâne sub controlul Namirial pe toată durata analizei.
Notă adăugată la publicare: pe 28 mai 2026, în timp ce acest articol era în curs de finalizare, Anthropic a lansat Opus 4.8 ca fiind cel mai performant model disponibil publicului larg. Modificările cele mai relevante pentru această lucrare nu se referă la capacitatea brută. Se raportează că Opus 4.8 face mai puține afirmații nefondate și semnalează mai ușor propria incertitudine, ceea ce are o influență directă asupra etapei de validare adversarială și a ratei de fals pozitive descrise mai sus, iar noua sa orchestrare paralelă a sub-agenților reflectă forma multi-agent pe care se bazează deja pipeline-ul nostru. Rezultatele din această postare au fost obținute pe Opus 4.7; re-stabilirea bazei de referință a fluxului de lucru pe 4.8 este următorul nostru pas imediat.
Ce am construit
Am proiectat un pipeline de securitate asistat de AI care rulează nouă agenți specializați în paralel pe bazele noastre de cod și apoi validează și consolidează rezultatele prin mai multe etape independente de review. Fără a intra prea mult în detalii tehnice, arhitectura urmează un principiu spre care comunitatea de securitate converge: separarea detecției rapide bazate pe pattern-uri, a reasoning-ului semantic profund și a validării adversariale ca etape distincte, în locul dependenței de un singur agent AI universal.
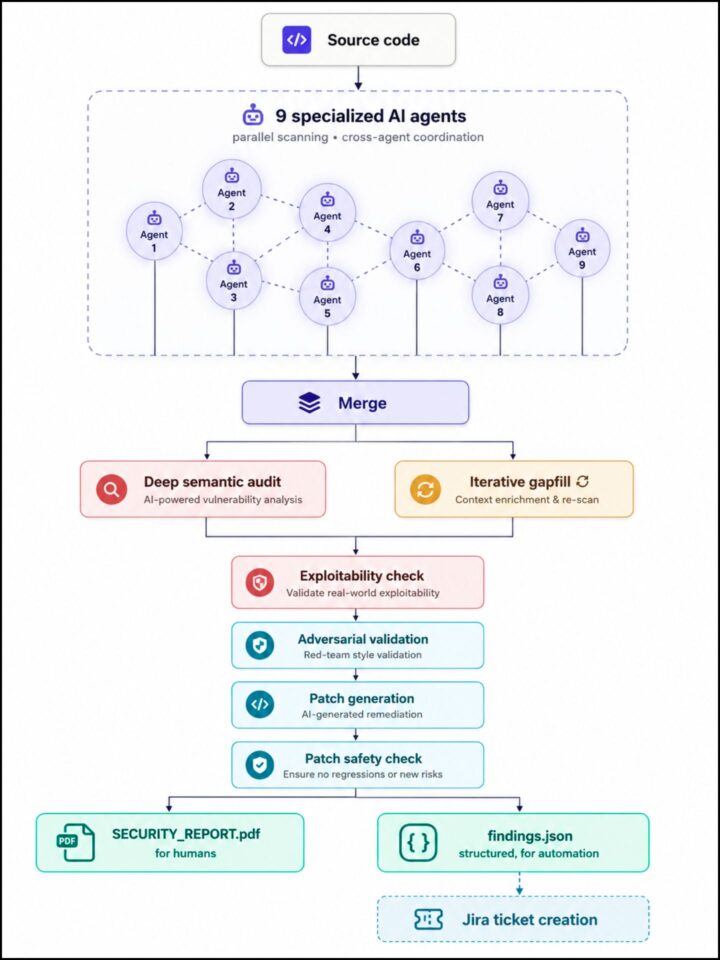
Pipeline-ul produce două output-uri: un raport PDF lizibil pentru oameni și un feed JSON structurat care deschide automat tichete în issue tracker-ul nostru, direcționând fiecare finding către echipa potrivită fără triere manuală. Această separare este mai importantă decât pare. AI-ul scoate la suprafață vulnerabilitățile, însă răspunsul de inginerie rămâne ancorat în workflow-ul nostru de dezvoltare existent.
Că arhitectura este surprinzător de similară cu abordările documentate în articole recente din industrie pe această temă. Convergența nu este o coincidență: aceasta este forma pe care trebuie să o aibă acest tip de muncă pentru a fi eficient. De asemenea, sugerează că cea mai importantă variabilă este arhitectura în sine – modul în care agenții sunt orchestrați, validați și combinați – cel puțin la fel de importantă precum modelul de bază utilizat.
Ce am descoperit
Am rulat pipeline-ul pe 23 de repository-uri interne, totalizând aproximativ 1,40 milioane de linii de cod. Același perimetru a fost scanat și de platforma noastră comercială SAST. Toate rezultatele de mai jos au fost obținute într-o perioadă de patru săptămâni, între mijlocul lunii aprilie și mijlocul lunii mai 2026.
Comparația principală este următoarea: la nivelul întregului perimetru, sistemul nostru comercial SAST a identificat 17 vulnerabilități de nivel ridicat sau critic, toate fiind deja triate și rezolvate prin procesul nostru standard de gestionare a vulnerabilităților. Fluxul de lucru bazat pe IA a generat 152 de potențiale vulnerabilități, dintre care 136 au fost confirmate de administratorii de cod și remediate ulterior, adică de 8,0 ori mai multe decât valoarea de referință a sistemului SAST.
Privind datele repository cu repository:
- În 22 din cele 23 de repository-uri, pipeline-ul AI a identificat mai multe finding-uri high sau critical decât SAST-ul comercial.
- În 15 din cele 23 de repository-uri, SAST-ul comercial a raportat zero finding-uri high sau critical, în timp ce pipeline-ul AI a identificat între 2 și 13 finding-uri confirmate în fiecare.
- Într-un repository, SAST-ul comercial a identificat puțin mai multe constatări decât pipeline-ul AI (4 față de 3). Este singurul caz din dataset-ul nostru în care instrumentul tradițional a depășit pipeline-ul AI, iar diferența este de un singur finding.
- Cele 17 finding-uri ale SAST-ului comercial au fost concentrate în doar 8 dintre cele 23 de repository-uri.
Ce a găsit pipeline-ul AI și ce analiza bazată pe pattern-uri nu putea detecta
Dintre cele 152 de constatări potențiale identificate de pipeline-ul AI, 70 (46%) au provenit exclusiv din etapa de audit semantic profund: vulnerabilități identificate de un agent care raționa asupra intenției codului și asupra fluxurilor de date între fișiere, nu prin pattern matching. Aceasta este categoria în care analiza AI adaugă o valoare pe care instrumentele tradiționale, structural, nu o pot furniza.
Celelalte 82 de finding-uri au provenit de la agenții paraleli specializați pe injection, deserializare, criptografie, SSRF, XXE, autentificare, autorizare, dependențe supply chain, infrastructure-as-code și exception handling.
Imaginea pe categorii
Cea mai importantă concluzie nu este raportul de 8,9× luat izolat, ci distribuția pe categorii. În cele cincisprezece repository-uri pe care SAST-ul comercial le-a declarat „clean”, pipeline-ul AI a identificat:
- Defecte de autentificare și autorizare cu lanțuri de ownership neobișnuite
- Operațiuni criptografice care utilizează algoritmul corect într-un mod greșit
- Încălcări ale trust boundaries unde date neîncredere influențează decizii de securitate între mai multe fișiere
- Exception handling fail-open pe căi critice
- Pattern-uri de design nesigure: întreaga categorie OWASP A06:2025 prin definiție
Cele 17 finding-uri identificate de SAST-ul comercial erau exact tipul de defect „clasic” unde pattern matching-ul cu reguli rafinate de-a lungul unui deceniu rămâne cu adevărat puternic. Nu susținem că instrumentul comercial este „defect”: el acoperă extrem de bine o bandă îngustă de risc și nu acoperă deloc o bandă mult mai largă.
Cele două abordări sunt complementare, nu substitutive. Roadmap-ul nostru păstrează SAST-ul comercial pentru categoriile bogate în pattern-uri, unde regulile sunt mature, și utilizează pipeline-ul AI pentru ceea ce doar acesta poate scoate la lumină.
Două cifre pe care le publicăm fără să le cosmetizăm:
- Etapa de validare adversarială respinge aproximativ 33% dintre finding-urile candidate. Înainte ca un finding să ajungă la un reviewer uman, un agent independent încearcă să îl infirme, acționând mai degrabă ca un peer reviewer sceptic decât ca un identificator de vulnerabilități. Aproximativ o treime dintre candidații marcați inițial nu supraviețuiesc acestei etape și sunt eliminați din raportul final. Cele 152 de finding-uri high/critical menționate mai sus sunt cele care au trecut această etapă. Considerăm această etapă o caracteristică pozitivă și nu un motiv de jenă: fără ea, rata de false positive vizibilă pentru ingineri ar fi semnificativ mai ridicată.
- Perimetrul comparat aici este subsetul bazei noastre de cod asupra căruia ambele instrumente au fost aplicate în condiții direct comparabile. SAST-ul nostru comercial acoperă în prezent repository-uri suplimentare asupra cărora pipeline-ul AI nu a fost încă rulat. Comparația este relevantă în propriul său domeniu, dar nu reprezintă un audit complet al întregii platforme.
Ce înseamnă acest lucru în practică
Cele patru săptămâni petrecute rulând acest pipeline pe repository-urile noastre ne-au condus la câteva concluzii practice.
Analiza de securitate AI multi-agent funcționează și funcționează bine atunci când arhitectura este proiectată corect. Pattern-ul care reiese din rezultatele noastre, din raportul Cloudflare și din munca Mozilla asupra Firefox este același: detecție paralelă specializată, audit semantic profund, validare adversarială și raportare structurată. Un singur agent universal produce rezultate considerabil mai slabe decât această abordare stratificată.
Tehnologia completează și nu înlocuiește soluțiile SAST tradiționale. Cele 17 finding-uri identificate de SAST-ul nostru comercial sunt reale și valoroase, iar regulile din spatele lor au fost rafinate pe parcursul a peste un deceniu de utilizare în producție. Cele 152 de finding-uri scoase la lumină de pipeline-ul AI sunt de asemenea reale și acoperă categorii pe care analiza bazată pe pattern-uri nu le poate detecta structural. Ambele își au locul într-un program serios de securitate.
Actualizarea OWASP Top 10:2025, cu noul accent pus pe eșecurile supply chain, gestionarea condițiilor excepționale și insecure design, întărește această complementaritate. Noile categorii sunt exact acelea în care analiza AI bazată pe reasoning aduce cea mai mare valoare și unde scanarea tradițională este cel mai puțin eficientă.
Ce urmează
Pipeline-ul nu este finalizat. Patru săptămâni de operare reprezintă începutul și nu concluzia acestei munci. În trimestrele următoare planificăm:
- să extindem acoperirea către repository-uri suplimentare dincolo de cele 23 actuale;
- să adăugăm un agent dedicat riscurilor OWASP LLM Top 10 (pentru componentele platformei noastre care integrează large language models);
- să consolidăm integrarea cu CI/CD-ul nostru, astfel încât scanările rapide să blocheze pull request-urile iar scanările complete să ruleze pe release branches, și re-stabilirea bazei de referință a fluxului de lucru pe Opus 4.8.
Privim securitatea asistată de AI ca pe o capabilitate permanentă și nu ca pe o inițiativă punctuală și vom continua să investim în aceasta pentru a accelera detectarea vulnerabilităților la viteza atacurilor moderne.
Această activitate a fost realizată de Giuseppe Gottardi cu sprijinul echipei sale de cybersecurity și de Gabriele Mariotti, Identity Technical Manager, Trust Services & Technologies, pentru validarea vulnerabilităților.





