

En las últimas semanas, tres anuncios han cambiado la conversación en torno a la inteligencia artificial y la ciberseguridad.
- Anthropic ha anunciado el Proyecto Glasswing, una iniciativa coordinada con AWS, Apple, Broadcom, Cisco, CrowdStrike, Google, JPMorgan Chase, la Fundación Linux, Microsoft, NVIDIA y Palo Alto Networks, respaldada por cien millones de dólares en créditos de uso, con el fin de aplicar Claude Mythos Preview al software más crítico del mundo. Mythos Preview es el modelo de vanguardia más potente de Anthropic, que la empresa ha decidido no hacer público.
- Mozilla utilizó el mismo modelo para identificar y corregir 271 vulnerabilidades en una sola versión de Firefox.
- Cloudflare publicó un informe detallado sobre su ejecución en más de cincuenta de sus propios repositorios de código.
El mensaje es inequívoco: el descubrimiento de vulnerabilidades asistido por IA ya no es experimental. Es una práctica defensiva que las organizaciones serias están adoptando ahora mismo.
En Namirial, comenzamos a construir nuestra respuesta a este desafío la misma semana en que Claude Opus 4.7 estuvo disponible de forma general, a mediados de abril de 2026. Cuatro semanas después, tenemos resultados que vale la pena compartir.
Por qué esto es importante para un trust service provider
Como Qualified Trust Service Provider bajo eIDAS, Namirial opera infraestructuras que el marco europeo clasifica explícitamente como críticas. Cada firma electrónica que generamos, cada identidad que verificamos, cada sello de tiempo que emitimos forma parte de la columna vertebral digital de la que dependen diariamente administraciones públicas, bancos, aseguradoras, sistemas sanitarios y millones de ciudadanos.
Esa posición implica un nivel de responsabilidad inusual. Las expectativas de seguridad depositadas en un QTSP son al menos tan altas como las exigidas a un proveedor global de servicios cloud, y el marco regulatorio, a través de eIDAS 2.0 y la directiva Critical Entities Resilience, exige una mejora continua y no simplemente cumplimiento puntual.
Como cualquier organización de ingeniería de nuestro tamaño, nuestra cadena de herramientas de seguridad incluye soluciones comerciales estándar del sector para SAST, análisis de dependencias, detección de secretos y un proceso estructurado de revisión de seguridad para las releases. Estas herramientas funcionan bien para aquello para lo que fueron diseñadas: detectar la larga cola de defectos basados en patrones conocidos, como inyecciones SQL, credenciales expuestas y dependencias vulnerables.
Lo que sistemáticamente no detectan es la categoría más compleja: fallos de lógica de negocio, cadenas de explotación multi-step, usos sutiles e incorrectos de criptografía, problemas de diseño y vulnerabilidades que abarcan múltiples archivos o módulos de maneras que el análisis basado en patrones no puede rastrear. Precisamente en esa brecha es donde un modelo de IA basado en reasoning – capaz de leer código, comprender intenciones y seguir flujos de datos a través de distintos límites – aporta un valor que las herramientas tradicionales, estructuralmente, no pueden ofrecer.
La lista OWASP Top 10:2025, finalizada en enero de 2026, mantiene «Diseño inseguro» (A06) e incorpora «Manejo incorrecto de condiciones excepcionales» (A10) como categorías que el análisis basado en patrones no puede detectar de forma estructural. Estas son precisamente las clases de hallazgos en las que el análisis de IA basado en el razonamiento aporta un valor añadido que las herramientas tradicionales no ofrecen.
El modelo que utilizamos
Claude Mythos Preview, el modelo de vanguardia más potente de Anthropic, se anunció el 7 de abril de 2026 en el marco del Proyecto Glasswing. El acceso se ha restringido a un grupo limitado de socios de la plataforma y no está disponible de forma generalizada. Nueve días después, el 16 de abril de 2026, Anthropic puso Opus 4.7 a disposición general.
Opus 4.7 es el modelo que utilizamos para la pipeline descrita en este artículo. No es Mythos y, a diferencia de Mythos, no ha demostrado la misma capacidad de vanguardia en tareas de seguridad. Sin embargo, es el modelo generalmente disponible más potente de Anthropic en el momento de escribir este texto, y queríamos entender qué podía lograrse con él sobre bases de código reales en producción.
El proceso se ejecuta en modelos de Claude alojados en regiones europeas de AWS a través de Amazon Bedrock, bajo condiciones comerciales que garantizan que nuestro código no se utilice para entrenar el modelo subyacente y no se conserve más allá de la operación de inferencia. Todo el material de origen permanece bajo el control de Namirial durante todo el análisis.
Nota añadida en el momento de la publicación: el 28 de mayo de 2026, mientras se ultimaba este artículo, Anthropic lanzó Opus 4.8 como su modelo de uso general más potente. Los cambios más relevantes para este trabajo no se refieren a la capacidad bruta. Según se informa, Opus 4.8 realiza menos afirmaciones sin fundamento y señala su propia incertidumbre con mayor facilidad, lo que incide directamente en la etapa de validación adversaria y en la tasa de falsos positivos descritas anteriormente, y su nueva orquestación de subagentes en paralelo refleja la estructura multiagente en la que ya se basa nuestro proceso. Los resultados de este artículo se obtuvieron con Opus 4.7; nuestro siguiente paso inmediato es volver a establecer la línea de base del proceso con la versión 4.8.
Qué construimos
Diseñamos un pipeline de seguridad asistida por IA que ejecuta nueve agentes especializados en paralelo sobre nuestras bases de código y posteriormente valida y consolida sus hallazgos a través de varias etapas independientes de revisión. Sin entrar en demasiados detalles de ingeniería, la arquitectura sigue un principio hacia el cual la comunidad de seguridad está convergiendo: separar la detección rápida basada en patrones, el reasoning semántico profundo y la validación adversarial como etapas distintas, en lugar de depender de un único agente de IA multipropósito.
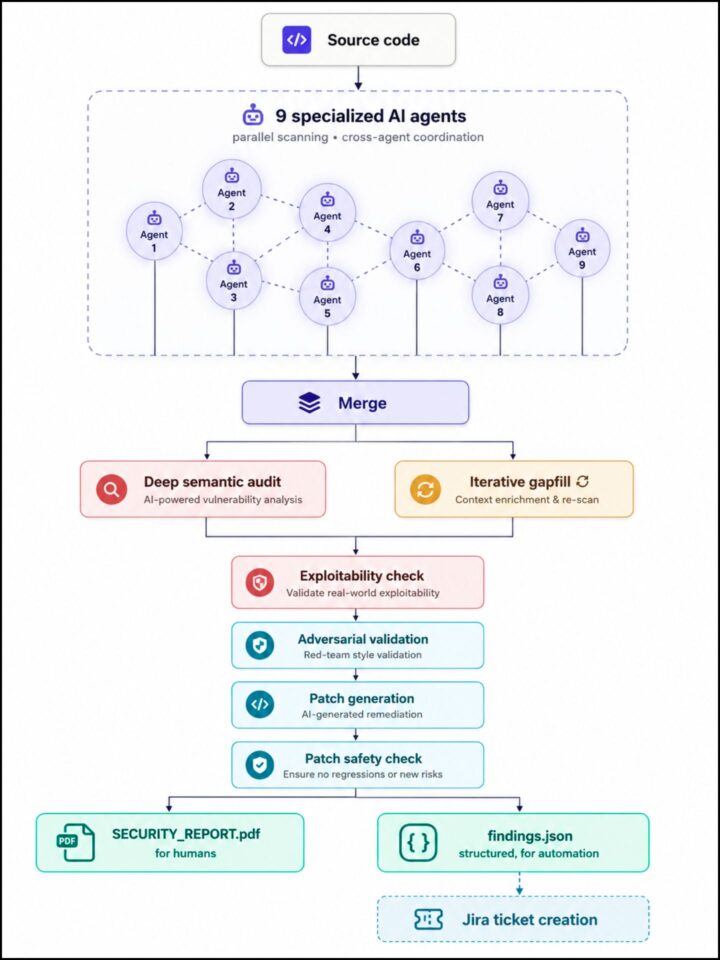
El pipeline produce dos outputs: un informe PDF legible por humanos y un feed JSON estructurado que abre automáticamente tickets en nuestro issue tracker, dirigiendo cada hallazgo al equipo adecuado sin necesidad de triage manual. Esta separación es más importante de lo que parece. La IA detecta vulnerabilidades, pero la respuesta de ingeniería permanece anclada en nuestro workflow de desarrollo existente.
La arquitectura es sorprendentemente similar a los enfoques documentados en recientes publicaciones de la industria sobre este tema. La convergencia no es casualidad: esta es la forma que este trabajo necesita adoptar para ser eficaz. También sugiere que la variable más importante es la arquitectura misma -cómo se orquestan, validan y combinan los agentes – al menos tanto como el modelo subyacente específico.
Qué encontramos
Ejecutamos el pipeline sobre 23 repositorios internos, con un total aproximado de 1,40 millones de líneas de código. El mismo perímetro fue analizado por nuestra plataforma comercial de SAST. Todos los resultados mostrados a continuación fueron obtenidos dentro de una ventana de cuatro semanas, entre mediados de abril y mediados de mayo de 2026.
La comparación principal es la siguiente: en todo el perímetro, nuestro SAST comercial identificó 17 hallazgos de gravedad alta o crítica, todos los cuales ya habían sido clasificados y resueltos mediante nuestro proceso estándar de gestión de vulnerabilidades. El proceso de IA generó 152 posibles hallazgos, de los cuales 136 fueron confirmados por los responsables del código y posteriormente corregidos, lo que supone 8,0 veces más que la referencia del SAST.
Observando los datos repositorio por repositorio:
- En 22 de los 23 repositorios, el pipeline de IA identificó más hallazgos high o critical que el SAST comercial.
- En 15 de los 23 repositorios, el SAST comercial reportó cero hallazgos high o critical, mientras que la pipeline de IA identificó entre 2 y 13 hallazgos confirmados en cada uno.
- En un repositorio, el SAST comercial identificó un número ligeramente superior de hallazgos que el proceso de IA (4 frente a 3). Es el único caso de nuestro dataset en el que la herramienta tradicional superó a la pipeline de IA, y la diferencia es de un único hallazgo.
- Los 17 hallazgos del SAST comercial estaban concentrados en solo 8 de los 23 repositorios.
Lo que el pipeline de IA encontró y que el escaneo basado en patrones no podía detectar
Dentro de los 152 hallazgos candidatos detectados por la pipeline de IA, 70 (46 %) provinieron exclusivamente de la etapa de auditoría semántica profunda: vulnerabilidades identificadas por un agente que razonaba sobre la intención del código y el flujo de datos entre archivos, y no mediante pattern matching. Esta es la categoría en la que el análisis basado en IA aporta un valor que las herramientas tradicionales, estructuralmente, no pueden proporcionar.
Los 82 hallazgos restantes provinieron de los agentes paralelos especializados en inyección, deserialización, criptografía, SSRF, XXE, autenticación, autorización, dependencias de supply chain, infrastructure-as-code y manejo de excepciones.
La visión categórica
La conclusión más importante no es el ratio de 8,9× por sí solo, sino la distribución por categorías. En los quince repositorios que el SAST comercial declaró como “clean”, la pipeline de IA detectó:
- Defectos de autenticación y autorización con cadenas de ownership no evidentes
- Operaciones criptográficas utilizando el algoritmo correcto de la manera incorrecta
- Violaciones de trust boundaries donde datos no confiables afectan decisiones de seguridad a través de múltiples archivos
- Manejo fail-open de excepciones en rutas críticas
- Patrones de diseño inseguros: toda la categoría OWASP A06:2025 por definición
Los 17 hallazgos identificados por el SAST comercial eran precisamente el tipo de defecto “de manual” donde el pattern matching con reglas refinadas durante más de una década sigue siendo realmente fuerte. No estamos argumentando que la herramienta comercial esté “rota”: cubre extremadamente bien una banda estrecha de riesgos y no cubre en absoluto una banda mucho más amplia.
Los dos enfoques son complementarios, no sustitutivos. Nuestra roadmap mantiene el SAST comercial para las categorías ricas en patrones donde sus reglas son maduras y utiliza el pipeline de IA para aquello que únicamente ella puede sacar a la luz.
Dos cifras que publicamos sin maquillarlas:
- La etapa de validación adversarial rechaza aproximadamente el 33 % de los hallazgos candidatos. Antes de que cualquier hallazgo llegue a un revisor humano, un agente independiente intenta refutarlo, actuando como un peer reviewer escéptico en lugar de como un descubridor. Aproximadamente un tercio de los candidatos inicialmente marcados no supera esta fase y es eliminado del informe final. Los 152 hallazgos high/critical citados anteriormente son los que sí la superaron. Consideramos esta fase una característica positiva y no una vergüenza: sin ella, la tasa de falsos positivos visible para los ingenieros sería sustancialmente más alta.
- El perímetro comparado aquí es el subconjunto de nuestra base de código donde ambas herramientas fueron aplicadas en condiciones directamente comparables. Nuestro SAST comercial cubre actualmente repositorios adicionales sobre los que la pipeline de IA aún no se ha ejecutado. La comparación es significativa dentro de su alcance, pero no constituye una auditoría completa de toda la plataforma.
Qué significa esto en la práctica
Las cuatro semanas que hemos pasado ejecutando esta pipeline sobre nuestros repositorios nos han dejado varias conclusiones prácticas.
El análisis de seguridad de IA multiagente funciona, y funciona bien, cuando la arquitectura está diseñada correctamente. El patrón que emerge de nuestros resultados, del informe de Cloudflare y del trabajo de Mozilla sobre Firefox es el mismo: detección paralela especializada, auditoría semántica profunda, validación adversarial e informes estructurados. Un único agente multipropósito produce resultados claramente peores que este enfoque por capas.
La tecnología complementa, en lugar de reemplazar, el SAST tradicional. Los 17 hallazgos identificados por nuestro SAST comercial son reales y valiosos, y las reglas detrás de ellos han sido refinadas durante más de una década de uso en producción. Los 152 hallazgos revelados por la pipeline de IA también son reales y cubren categorías que el análisis basado en patrones, estructuralmente, no puede detectar. Ambos pertenecen a un programa de seguridad serio.
La actualización del OWASP Top 10:2025, con su nuevo énfasis en fallos de supply chain, manejo de condiciones excepcionales e insecure design, refuerza esta complementariedad. Las nuevas categorías son precisamente aquellas donde el análisis de IA basado en reasoning aporta más valor y donde el escaneo tradicional es menos eficaz.
Qué viene después
La pipeline no está terminada. Cuatro semanas de operación representan el comienzo, no la conclusión de este trabajo. Durante los próximos trimestres planeamos:
- ampliar la cobertura a repositorios adicionales más allá de los 23 actuales;
- añadir un agente dedicado a los riesgos OWASP LLM Top 10 (para los componentes de nuestra plataforma que integran large language models);
- reforzar la integración con nuestro CI/CD para que los escaneos rápidos bloqueen pull requests y los escaneos completos se ejecuten sobre ramas de release, y volver a establecer la línea de base del proceso con Opus 4.8.
Consideramos la seguridad asistida por IA una capacidad permanente, no una iniciativa puntual, y seguiremos invirtiendo en ella para impulsar la detección de vulnerabilidades a la velocidad de los ataques modernos.
Este trabajo fue realizado por Giuseppe Gottardi con el apoyo de su equipo de ciberseguridad y por Gabriele Mariotti, Identity Technical Manager, Trust Services & Technologies, para la validación de vulnerabilidades.





